星语课程网
水利数字孪生模型
来源:本站编辑
12分钟前
0
很多数字孪生水利项目里,专业模型这一章都写得差不多: > 集成水文模型、水动力模型、调度模型和风险评估模型,支撑防洪预报、预警、预演、预案。 这句话没有错。 但问题是,它太容易写空。 真正到项目实施时,业主最关心的不是“有没有模型”,而是: 模型怎么接进平台? 输入数据从哪里来? 边界条件谁来配? 模型运行环境能不能复制? 计算结果怎么回到业务系统? 一次预演能不能复盘、追溯、校验? 这些问题回答不上来,模型就算放进系统,也只是“能演示”,很难“能实战”。 SL/T 863—2026《数字孪生水利专业模型集成与服务技术要求》给了一个很清楚的方向:专业模型集成不是简单接一个程序,而是要围绕**输入输出、模型封装、模型登记与测试、服务发布与调用**形成一套工程化机制。标准目录中也专门设置了“输入输出要求、封装要求、模型登记与测试、服务发布与调用”等章节,说明模型集成的重点已经从“模型存在”转向“模型服务化”。 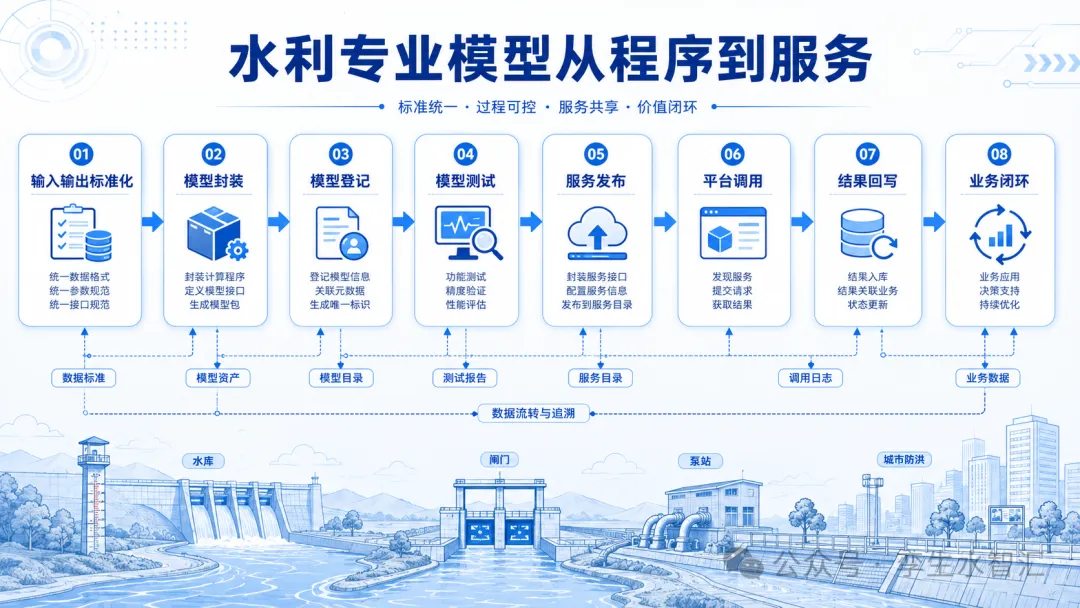 这篇就拿防洪预演这个最常见的场景,把这件事讲透一点。 * * * ## 01 防洪预演真正要跑的,不是一个模型,而是一条模型链 --------------------------- 先看一个典型场景。 未来6小时有强降雨。上游有水库,中游有河道和闸站,下游有城区、低洼村庄和蓄滞洪区。 水利部门要判断: 这场雨会不会形成洪水? 哪个断面什么时候超警? 水库要不要预泄? 闸门怎么开? 下游淹没范围有多大? 不同调度方案哪个风险更小? 这时候平台要跑的不是单个模型,而是至少一条模型链: **降雨输入 → 水文产汇流 → 河道水动力演进 → 工程调度 → 淹没分析 → 风险评估 → 方案比选 → 预案任务** 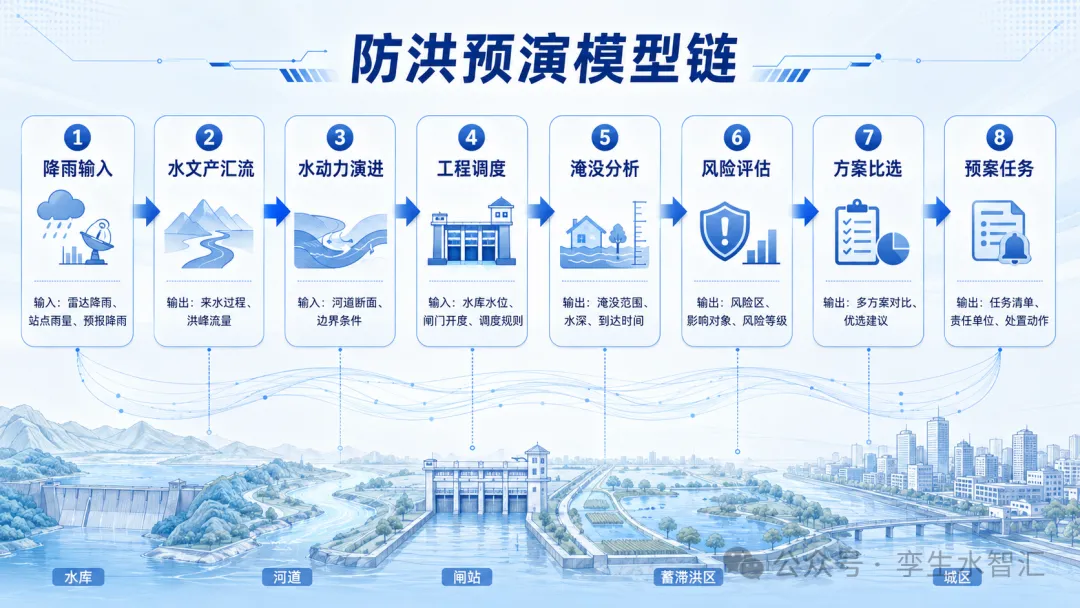 如果只接一个水动力模型,最多解决“河道里水怎么走”。 如果没有前端水文模型,降雨无法变成入流过程; 如果没有调度模型,水库、闸站、泵站只能当静态对象; 如果没有风险评估模型,淹没图无法转成影响人口、重点设施、道路中断等业务结果; 如果没有服务化调用,平台就只能人工跑模型、人工导结果。 所以,防洪预演的技术难点,不是“有没有模型”,而是**多个模型之间能不能按统一规则接起来**。 * * * ## 02 第一件事:把模型输入输出说清楚 ------------------ 很多项目模型接不起来,第一关就卡在输入输出。 水文模型要什么输入? 水动力模型要什么输入? 调度模型要什么输入? 风险评估模型要什么输入? 如果这些东西不提前定义清楚,后面一定靠人工补。 SL/T 863—2026把模型输入输出单独列为一章,并进一步拆到基础数据、模型参数数据、初始条件数据、边界条件数据、相关内容示例等内容;附录中还给出了输入输出数据示例,涉及一维水动力模型、二维水动力模型、蓄滞洪区、出口边界、断面信息、河道断面拓扑等多类数据表。 落到防洪预演项目里,至少要把下面这些数据说清楚。 ### 1\. 基础数据 包括流域边界、河道中心线、河道断面、DEM、堤防高程、水库库容曲线、闸站位置、泵站能力、蓄滞洪区边界、承灾体数据等。 这类数据决定模型的空间底座。 如果断面旧、DEM粗、闸站位置不准,模型结果再漂亮也不敢用。 ### 2\. 模型参数数据 包括糙率、产流参数、汇流参数、闸门流量系数、水库调度规则、泵站启停规则等。 参数不是随便填的。 同一条河,不同河段糙率不同;同一个流域,不同下垫面产流参数不同。 如果参数没有来源、没有版本、没有校验记录,模型结果就很难进入会商。 ### 3\. 初始条件数据 包括起算时刻水位、流量、水库水位、闸门开度、泵站状态、蓄滞洪区当前状态等。 这部分最容易被忽略。 实际防洪预演不是从“空白世界”开始,而是从当前真实水情、工情开始。初始水位差20厘米,下游淹没边界可能就不一样。 ### 4\. 边界条件数据 包括上游入流过程、下游水位过程、支流汇入、降雨过程、外江潮位、闸坝控制条件等。 水文模型和水动力模型衔接,最关键的就是边界条件。 很多项目所谓“水文水动力耦合”,实际只是人工把一个Excel流量过程线导进去。演示能做,实战很难稳定运行。 * * * ## 03 第二件事:统一数据格式,不要让模型靠“手工倒文件”运行 ------------------------------ 模型之间接不起来,常见原因不是模型本身不行,而是数据格式混乱。 水文模型输出一个Excel。 水动力模型要一个自定义文本。 调度模型读数据库。 风险评估模块要GeoJSON。 平台最后再把结果转成图片或图层。 每一步都能做,但每一步都要人工盯。 一到实战,多方案、多轮次、多情景滚动计算时,人工转换马上成为瓶颈。 SL/T 863—2026在输入输出格式上提出了文件格式要求,其中对 NetCDF 和 JSON 这类格式作了专门要求;从标准中的示例看,NetCDF更适合承载网格、时序、多维数组类模型数据,JSON更适合传递参数、配置和轻量级结构化内容。 放到防洪预演里,可以这样理解: ### NetCDF更适合放这些数据 * 二维水动力网格结果; * 水深、水位、流速、流向时序数据; * 淹没范围动态过程; * 多时刻、多网格、多变量计算结果。 ### JSON更适合放这些数据 * 模型任务参数; * 起止时间; * 方案编号; * 闸门开度配置; * 水库调度规则选择; * 模型运行状态; * 结果文件索引。 这件事看起来很技术,但项目中非常关键。 因为只要数据格式不统一,模型链就无法稳定自动化。 防洪预演不是跑一次模型,而是要在汛期反复跑、滚动跑、对比跑。格式不统一,系统就会退回“人工值守型模型平台”。 * * * ## 04 第三件事:模型要封装,不要依赖某台电脑、某个人、某个目录 ------------------------------- 很多项目里,模型其实能跑。 但只能在原厂工程师电脑上跑。 换一台服务器,缺库; 换一个目录,找不到文件; 换一个操作系统,环境崩; 换一个版本,结果不一致。 这类问题在验收演示时不明显,但一到运维阶段非常致命。 SL/T 863—2026专门设置“封装要求”,并引入容器技术、模型封装等相关内容;标准术语部分也解释了容器技术和模型封装,后续附录还给出了模型封装示例。 这对项目实施有一个很直接的要求: **模型不能只交付一个可执行程序,而要交付可复现的运行单元。** 至少要包括: * 模型程序; * 依赖库; * 运行环境; * 输入目录约定; * 输出目录约定; * 启动命令; * 参数说明; * 日志输出; * 异常退出机制; * 版本号。 简单说,就是模型要能被平台稳定调用,而不是靠工程师远程桌面去点按钮。 * * * ## 05 第四件事:模型登记,不是填个名称,而是建立模型资产台账 ------------------------------ 很多平台有“模型库”,但里面只是几张卡片: 水文模型。 水动力模型。 调度模型。 风险评估模型。 这不叫模型管理。 真正的模型登记,至少要回答这些问题: 这个模型解决什么业务问题? 适用范围是什么? 输入数据是什么? 输出结果是什么? 运行环境是什么? 版本号是多少? 开发单位是谁? 计算资源要求是什么? 是否通过测试? 典型算例是什么? 和哪些业务模块有关? SL/T 863—2026设置了“模型登记与测试”章节,要求模型登记、测试等内容进入标准化管理,并在附录中给出了模型登记示例;从附录表格可以看到,登记信息不只是模型名称,还涉及模型分类、模型版本、开发信息、运行环境、输入输出、服务信息等内容。 这件事在防洪预演里很重要。 因为同一个系统可能有多个模型版本: 历史洪水复盘模型; 实时洪水预报模型; 快速预演模型; 精细水动力模型; 区县简化模型; 流域级联合调度模型。 不同模型的精度、耗时、适用场景不一样。 如果不登记清楚,业务人员根本不知道什么时候该用哪个模型。 * * * ## 06 第五件事:模型测试不能只看“能不能跑通” ----------------------- 模型测试如果只看“程序能不能跑完”,是不够的。 防洪预演模型至少要测四类内容。 ### 1\. 输入检查 缺少雨量数据怎么办? 断面数据不完整怎么办? 闸门开度为空怎么办? 上下游边界时间步长不一致怎么办? 模型不能直接崩溃,要能返回明确错误。 ### 2\. 运行检查 是否成功启动? 是否超时? 是否生成日志? 是否中断? 是否返回计算状态? 项目里最怕的是模型后台已经失败,前端还显示“计算中”。 ### 3\. 结果检查 输出文件是否生成? 时间序列是否完整? 水位、流量、水深是否在合理范围? 是否出现异常负值、跳变值、空值? 这一步是质量控制,不是页面展示。 ### 4\. 算例校验 是否用历史洪水做过校验? 洪峰流量误差是多少? 峰现时间偏差是多少? 关键断面水位误差是多少? 淹没范围与历史调查是否一致? 如果没有算例校验,模型结果很难被业务人员采信。 * * * ## 07 第六件事:模型发布成服务,才能真正进入“四预” -------------------------- 很多项目里,模型集成到最后,还是“平台调用脚本”。 这不够。 从数字孪生平台角度看,模型应该变成服务: 平台发起任务; 模型服务接收参数; 服务拉取输入数据; 模型计算; 服务返回状态; 结果入库或发布为图层; 业务模块继续调用结果。 SL/T 863—2026设置了“服务发布与调用”章节,要求模型服务发布、模型服务调用、服务调用要求等内容形成规范化机制。 防洪预演中,一个比较合理的服务链应该是这样: ### 第一步:创建预演任务 参数包括: * 任务名称; * 起算时间; * 预报时段; * 降雨方案; * 调度方案; * 模型链选择; * 计算精度; * 输出指标。 ### 第二步:调用水文模型服务 输入降雨、下垫面、前期土壤湿度等数据; 输出关键断面流量过程线。 ### 第三步:调用水动力模型服务 输入流量过程线、河道断面、下游边界、闸坝控制条件; 输出水位、流速、水深、淹没范围。 ### 第四步:调用调度模型服务 根据水库、闸站、泵站、蓄滞洪区规则,生成或校核调度方案。 ### 第五步:调用风险评估服务 叠加人口、道路、重点设施、农田、企业、学校、医院等承灾体; 输出风险清单和影响统计。 ### 第六步:调用方案比选服务 比较不同方案下的水位峰值、超警时间、淹没面积、影响人口、重点设施风险、工程安全压力和处置成本。 这一套跑通,才叫防洪预演进入业务。 * * * ## 08 防洪预演最容易卡住的,其实是模型之间的“接口契约” ---------------------------- 如果只从项目角度讲,SL/T 863—2026给我的最大启发不是“用什么格式”,也不是“是否容器化”。 而是四个字: **接口契约。** 每个模型都要说清楚: 我需要什么输入; 我接受什么格式; 我怎么启动; 我输出什么结果; 我失败时返回什么; 我计算结果怎么被下游继续使用。 这件事比页面设计重要得多。 因为防洪预演的链条不是单模型闭环,而是多模型串联: 水文模型输出不规范,水动力模型就接不上; 水动力模型输出不规范,淹没分析就接不上; 淹没分析输出不规范,风险评估就接不上; 风险评估输出不规范,方案比选就没法量化; 方案比选结果不规范,预案和工单就接不下去。 很多项目看似卡在“业务应用不好用”,本质上是模型服务接口没设计好。 * * * 09 项目方案里,建议把“模型集成”写成这几张表 ------------------------ 如果要让方案更专业,不建议只写一段“建设模型库”。 可以直接写成表。 ### 表1:模型清单表 |模型名称|业务用途|输入|输出|调用方式|适用场景| |------------|------------|------------|------------|------------|------------| |水文模型|降雨产汇流计算|降雨、下垫面、土壤湿度|断面流量过程线|服务调用|流域洪水预报| |水动力模型|河道洪水演进|流量边界、断面、糙率|水位、流速、淹没范围|服务调用|洪水预演| |调度模型|水库闸站联合调度|工程状态、调度规则|调度方案、泄流过程|服务调用|方案比选| |风险评估模型|影响分析|淹没范围、承灾体|影响人口、风险清单|服务调用|预警与预案| ### 表2:模型输入输出表 |模型|关键输入|关键输出|建议格式| |------------|------------|------------|------------| |水文模型|降雨时序、子流域参数|流量过程线|JSON / NetCDF| |水动力模型|边界流量、断面、糙率|水位、水深、流速、淹没范围|NetCDF| |调度模型|水库水位、闸门开度、规则约束|调度过程、工程操作建议|JSON| |风险评估模型|淹没范围、承灾体数据|风险等级、影响统计|JSON / GIS图层| ### 表3:模型服务登记表 |登记项|内容| |------------|------------| |模型名称|XX流域一维/二维水动力模型| |模型版本|V1.0 / V1.1| |模型分类|水动力模型| |开发单位|XXX| |运行环境|Linux / Python / Fortran / Docker| |输入格式|NetCDF / JSON| |输出格式|NetCDF / JSON| |计算资源|CPU核数、内存、GPU需求| |典型耗时|10分钟 / 30分钟 / 1小时| |适用场景|洪水演进、淹没分析、方案比选| |校验记录|历史洪水场次、误差指标| 这比一句“集成专业模型”更像真正的工程方案。 * * * 10 验收时,建议重点问这10个问题 ------------------ 如果我是评审专家或业主,看防洪预演模型集成,不会只看动画。 我会问下面这些问题。 ### 1\. 模型有没有服务化? 是平台调用模型服务,还是人工打开软件运行? ### 2\. 输入输出有没有标准化? 水文模型输出能不能自动进入水动力模型? ### 3\. 模型有没有封装? 换服务器、换目录、换操作系统后还能不能稳定运行? ### 4\. 模型有没有登记? 模型版本、适用范围、开发单位、运行环境、输入输出是否有台账? ### 5\. 模型有没有测试? 是否有测试算例、测试报告、异常处理机制? ### 6\. 计算任务能不能追溯? 一次预演用了什么数据、什么参数、什么模型版本、什么调度规则? ### 7\. 工程调度是否进入计算? 水库、闸门、泵站、蓄滞洪区是动态参与计算,还是只在图上展示? ### 8\. 多方案能不能自动对比? 能不能同时比较方案A、B、C的水位峰值、超警时间、淹没范围和影响对象? ### 9\. 结果能不能进入业务? 模型结果能不能进入预警、会商、调度、派单和复盘? ### 10\. 模型能不能运维? 模型参数、版本、日志、错误、算例、服务状态能不能持续管理? 这10个问题,比“页面好不好看”更能判断一个项目有没有实战价值。 * * * 11 写在最后:SL/T 863真正解决的是模型工程化问题 ----------------------------- SL/T 863—2026的价值,不是告诉大家水文模型、水动力模型本身怎么推公式。 它真正解决的是另一个问题: **水利专业模型怎么进入数字孪生平台,变成稳定、可调用、可管理、可追溯的服务。** 这也是很多数字孪生水利项目的短板。 模型不是没有。 很多单位都有模型。 难的是: 模型输入输出不统一; 模型运行环境不可复制; 模型版本没有管理; 模型测试没有记录; 模型结果不能追溯; 模型服务不能被业务系统稳定调用。 所以,防洪预演要做实,不是多加几个模型名称,也不是多做几张效果图。 关键是把模型变成服务,把服务接入流程,把流程跑成业务。  一场暴雨来了,系统能不能自动组织数据、调用模型、生成结果、比选方案、输出任务。 这才是专业模型集成的真正价值。 也是数字孪生水利从“平台展示”走向“业务实战”的关键一步。 * * * 文末互动 ==== 你认为当前项目里,水利专业模型最容易卡在哪一步? A. 输入输出数据不统一 B. 模型运行环境不可复制 C. 水文模型和水动力模型衔接困难 D. 调度规则难以模型化 E. 模型结果无法追溯 F. 模型服务没有进入业务流程 欢迎留言讨论。
点赞
热门评论
最新评论
匿名用户
+1
-1
·
回复TA
暂无热门评论
相关推荐
阅读更多资讯
热门评论 最新评论
暂无热门评论