星语课程网
Timescaledb时间序列数据库使用指南
来源:本站编辑
2025-07-17 20:31
104
**关键词标签:** `时间序列数据库技术` `TSDB` `数据存储` `性能优化` `架构设计` `最佳实践` #### 第一章:引言与概述 ##### 1.1 时间序列数据的重要性 在数字化时代,时间序列数据无处不在。从服务器性能监控、股票价格变化、物联网传感器数据,到用户行为分析,这些按时间顺序产生的数据点构成了现代信息系统的重要组成部分。 时间序列数据具有以下典型特征: * **时间维度**:每个数据点都包含时间戳 * **高频写入**:数据产生频率高,写入密集 * **批量读取**:通常按时间范围进行查询 * **数据量大**:随时间累积,数据量呈指数级增长 ##### 1.2 传统数据库的局限性 传统关系型数据库在处理时间序列数据时面临诸多挑战: **性能瓶颈** * 写入性能:无法应对高频率数据写入 * 查询效率:时间范围查询性能不佳 * 存储开销:数据冗余,存储成本高 **功能局限** * 缺乏时间序列专用函数 * 聚合计算能力有限 * 数据压缩效率低 **运维复杂性** * 分区管理困难 * 数据过期清理复杂 * 扩展性差 ##### 1.3 时间序列数据库的价值 时间序列数据库(Time Series Database, TSDB)专门为时间序列数据而设计,提供了以下核心价值: * **极致性能**:针对时间序列数据优化的存储和查询引擎 * **高效压缩**:专用压缩算法,存储效率提升10-100倍 * **丰富功能**:内置时间序列分析函数和操作符 * **易于运维**:自动化数据管理和运维功能 * * * #### 第二章:时间序列数据库核心概念 ##### 2.1 基本概念与术语 **时间戳(Timestamp)** * 数据点的时间标识符 * 通常使用Unix时间戳或ISO 8601格式 * 精度可达纳秒级别 **指标(Metric)** * 被测量的具体项目 * 例如:CPU使用率、内存占用、网络流量 **标签(Tags/Labels)** * 用于标识和分类时间序列的键值对 * 例如:server=web01, region=us-east-1 **数据点(Point)** * 由时间戳、指标名称、标签和值组成的最小数据单元 数据点结构示例: { "timestamp": "2024-01-15T10:30:00Z", "metric": "cpu.usage.percent", "tags": { "server": "web01", "region": "us-east-1" }, "value": 85.6 } ##### 2.2 数据模型特点 时间序列数据库采用专门的数据模型来优化时间序列数据的存储和查询: **时间序列(Time Series)** 一个时间序列由指标名称和唯一的标签组合定义,包含按时间排序的数据点序列。 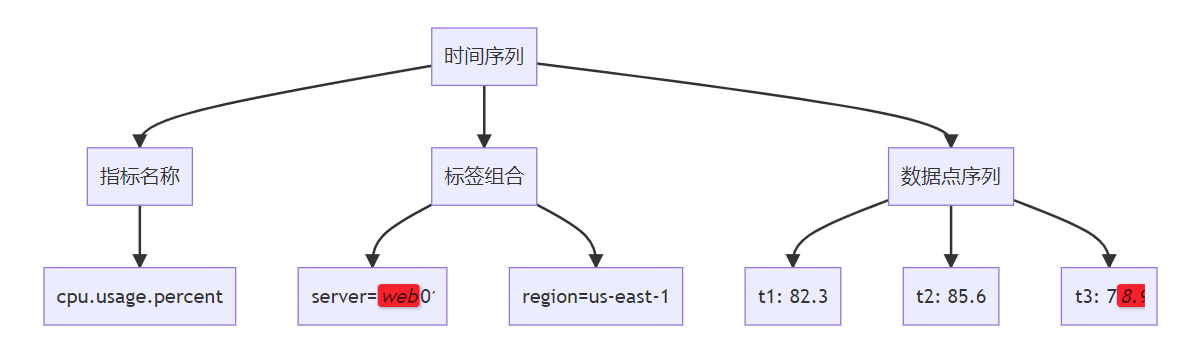 t3: 78.9 **基数(Cardinality)** 基数是指唯一时间序列的数量,由指标名称和标签的组合决定。高基数会影响数据库性能,需要合理设计标签结构。 ##### 2.3 查询模式分析 时间序列数据库的查询模式具有明显特点: **时间范围查询** * 大多数查询都包含时间范围条件 * 通常查询最近的数据 **聚合计算** * 频繁进行聚合操作:平均值、最大值、最小值、求和 * 时间窗口聚合:按小时、天、月进行汇总 **多序列操作** * 同时查询多个相关时间序列 * 进行序列间的计算和比较 * * * #### 第三章:核心技术原理 ##### 3.1 数据存储原理 时间序列数据库采用多种技术来优化数据存储: **时间分区(Time Partitioning)** 按时间将数据分割到不同的存储分区中,提高查询效率和管理便利性。 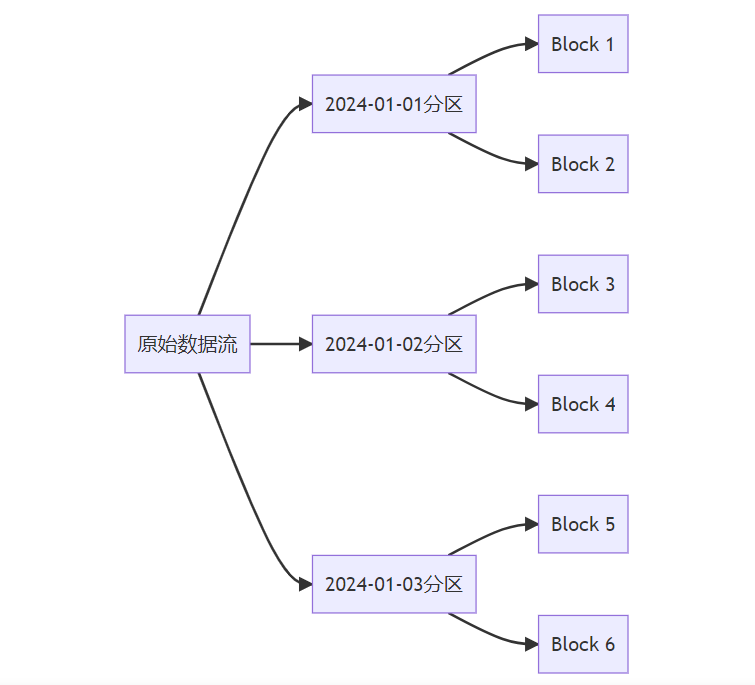 **列式存储** 将相同类型的数据存储在一起,提高压缩率和查询性能。 **时间序列分组** 将具有相同标签组合的数据点连续存储,减少磁盘随机访问。 ##### 3.2 压缩算法技术 时间序列数据具有很强的规律性,适合使用专门的压缩算法: **增量编码(Delta Encoding)** * 存储相邻时间戳或数值的差值 * 对于等间隔时间序列效果显著 **变长编码(Variable-Length Encoding)** * 对小数值使用较少的存储空间 * 常用算法:Varint、LEB128 **浮点数压缩** * Gorilla算法:Facebook开源的浮点数压缩算法 * 利用浮点数的时间局部性进行压缩 **批量压缩** * 对一批数据点进行整体压缩 * 通常能达到10:1到100:1的压缩比 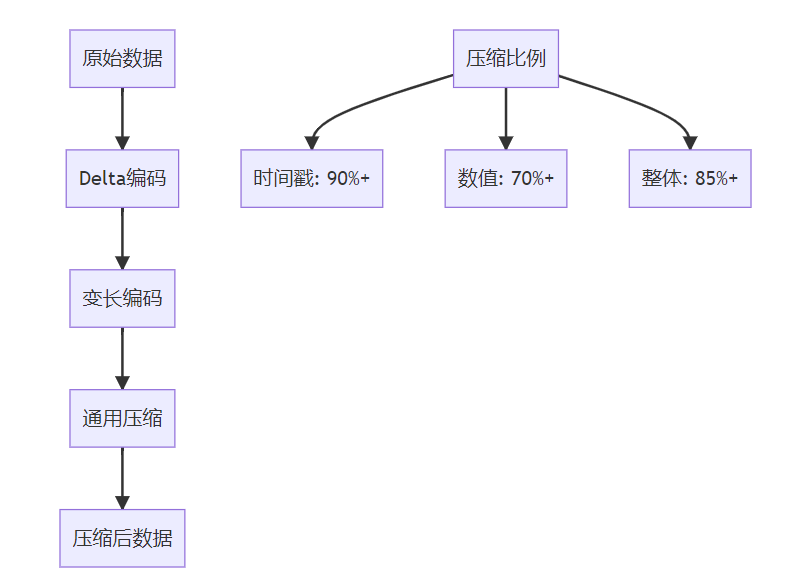 ##### 3.3 索引机制设计 高效的索引是时间序列数据库性能的关键: **时间索引** * B+树或LSM树索引时间戳 * 支持快速的时间范围查询 **标签索引** * 倒排索引标签键值对 * 支持复杂的标签过滤查询 **复合索引** * 结合时间和标签的复合索引 * 优化常见查询模式 * * * #### 第四章:架构设计深度解析 ##### 4.1 整体架构设计 现代时间序列数据库通常采用分层架构设计: 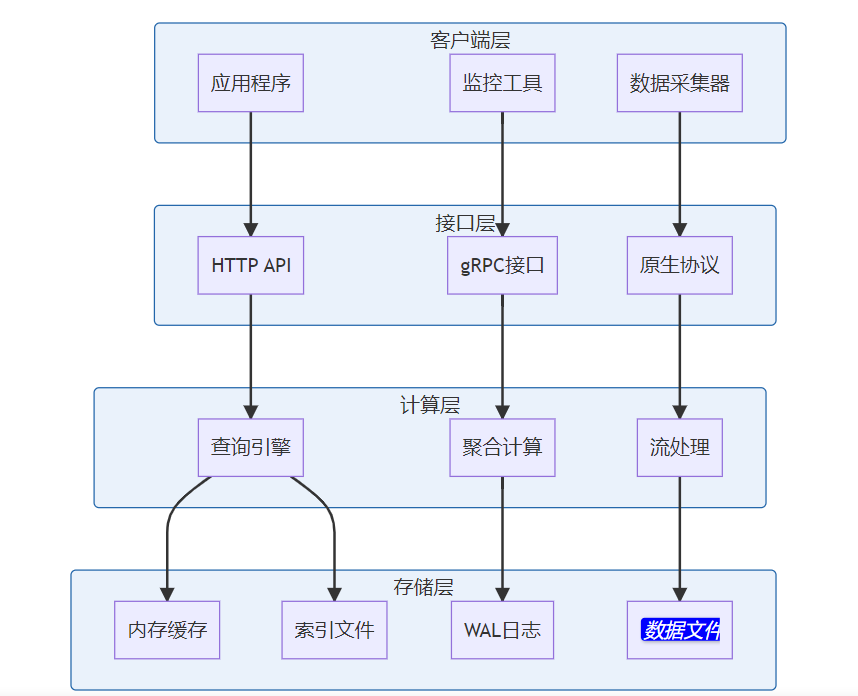 ##### 4.2 分布式架构 大规模时间序列数据库需要分布式架构来处理海量数据: **数据分片(Sharding)** * 按时间分片:不同时间段的数据存储在不同节点 * 按序列分片:不同时间序列分布到不同节点 * 混合分片:结合时间和序列的分片策略 **副本策略** * 多副本保证数据可靠性 * 读写分离提高查询性能 * 异地容灾保证业务连续性 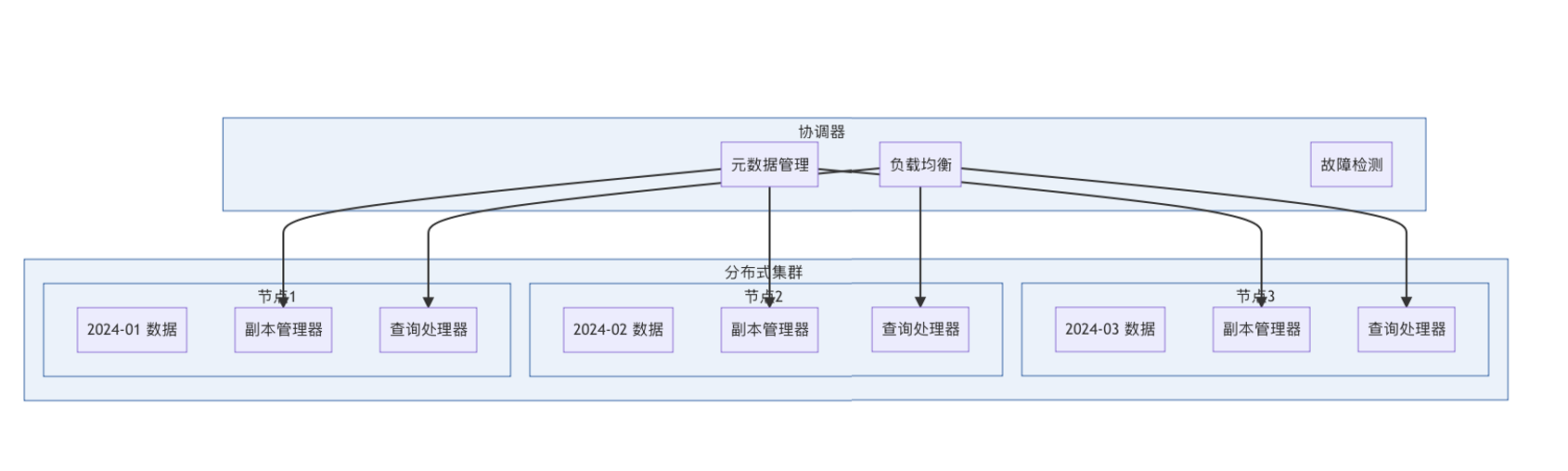 ##### 4.3 存储引擎设计 存储引擎是时间序列数据库的核心组件: **LSM树存储引擎** * 优化写入性能 * 适合高频数据写入场景 * 需要定期合并压缩 **B+树存储引擎** * 优化读取性能 * 支持事务特性 * 写入性能相对较低 **混合存储引擎** * 热数据使用内存存储 * 温数据使用SSD存储 * 冷数据使用机械硬盘或对象存储 * * * #### 第五章:主流产品技术对比 ##### 5.1 产品生态概览 当前时间序列数据库市场百花齐放,主要产品包括: **开源产品** * InfluxDB:功能丰富,易于使用 * Prometheus:云原生监控专用 * TimescaleDB:基于PostgreSQL扩展 * OpenTSDB:基于HBase的分布式方案 **商业产品** * AWS Timestream:云原生serverless * Google Cloud Bigtable:大规模分布式 * Azure Time Series Insights:集成Azure生态 ##### 5.2 技术特性对比 | 特性 |InfluxDB |Prometheus |TimescaleDB | OpenTSDB | | ------------ | ------------ | ------------ | ------------ | ------------ | | 存储引擎| TSM| LevelDB | PostgreSQL| HBase | | 查询语言 | InfluxQL/Flux|PromQL|SQL|HTTP API| | 分布式 | 企业版支持 | 原生支持 | 原生支持 | | |联邦模式 | 原生支持 | 原生支持 | 原生支持 | | | 压缩率 | 90%+|80%+|85%+|70%+| | 写入性能 | 极高 | 高 | 高 | 极高 | | 查询性能 | 高 | 极高 | 极高 | 中等 | | 运维复杂度 | 低 | 中等 | 中等 | 高 | ##### 5.3 性能基准测试 基于标准化测试环境的性能对比: **写入性能测试** * 测试环境:16核CPU,64GB内存,SSD存储 * 数据规模:1000万数据点/小时 * 并发度:100个写入线程 | 数据库 | 写入速率 (点 / 秒)|CPU 使用率 | 内存使用率 | | ------------ | ------------ | ------------ | ------------ | |InfluxDB|500,000|45%|35%| |TimescaleDB|350,000|55%|40%| |OpenTSDB|400,000|50%|30%| **查询性能测试** * 查询类型:时间范围查询 + 聚合计算 * 数据量:1TB时间序列数据 * 查询并发:50个并发查询 | 数据库 | 平均响应时间 (ms)|99 分位响应时间 (ms)|QPS| | ------------ | ------------ | ------------ | ------------ | |InfluxDB|150|800|300| |Prometheus|120|600|400| |TimescaleDB|100|500|450| * * * #### 第六章:最佳实践指南 ##### 6.1 数据建模最佳实践 **合理设计标签结构** ✅ **推荐做法** 指标:http_requests_total 标签:{method="GET", endpoint="/api/users", status="200"} ❌ **避免做法** 指标:http_requests_total_GET_api_users_200 标签:{timestamp="1609459200"} // 时间戳不应作为标签 **控制标签基数** * 避免使用用户ID、会话ID等高基数标签 * 合理分组相似的标签值 * 定期监控标签基数增长 **命名规范** * 使用点号分隔的层级命名:`service.component.metric` * 标签名使用下划线:`instance_id`,`region_name` * 保持命名一致性和可读性 ##### 6.2 查询优化策略 **利用时间范围过滤** -- 优化前:全表扫描 SELECT avg(value) FROM metrics WHERE tags->>'service' = 'web'; -- 优化后:时间范围过滤 SELECT avg(value) FROM metrics WHERE time >= '2024-01-01' AND time < '2024-01-02' AND tags->>'service' = 'web'; **使用合适的聚合窗口** -- 避免过小的聚合窗口导致性能问题 SELECT time_bucket('1h', time) as hour, avg(value) as avg_value FROM metrics WHERE time >= now() - interval '7 days' GROUP BY hour; **预聚合策略** 对于频繁查询的指标,可以预先计算并存储聚合结果: 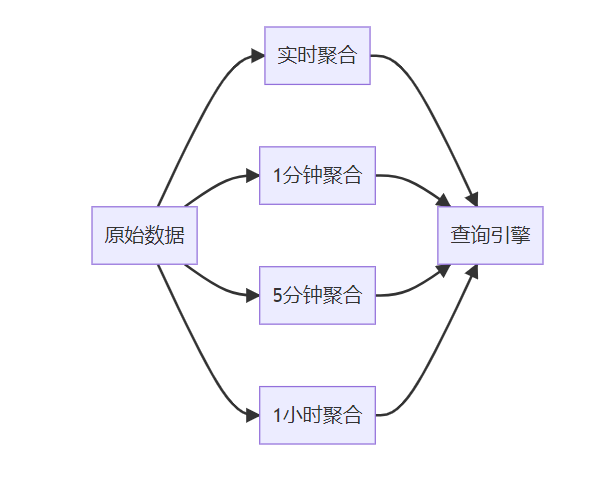 ##### 6.3 运维管理规范 **数据保留策略** retention_policies: - name: "real_time" duration: "7d" precision: "1s" - name: "historical" duration: "90d" precision: "1m" - name: "archive" duration: "2y" precision: "1h" **监控告警配置** * 写入速率监控 * 查询性能监控 * 存储空间监控 * 集群健康状态监控 **备份恢复策略** * 定期全量备份 * 实时增量备份 * 跨区域备份 * 备份有效性验证 * * * #### 第七章:性能优化策略 ##### 7.1 写入性能优化 **批量写入** 避免单条记录写入,使用批量写入提高吞吐量: # 批量写入示例 points = [] for i in range(1000): point = { "measurement": "cpu_usage", "tags": {"host": f"server{i%10}"}, "fields": {"value": random.uniform(0, 100)}, "time": datetime.utcnow() } points.append(point) client.write_points(points) # 批量提交 **写入缓冲优化** * 增大写入缓冲区大小 * 调整刷盘频率 * 使用异步写入模式 **负载均衡** 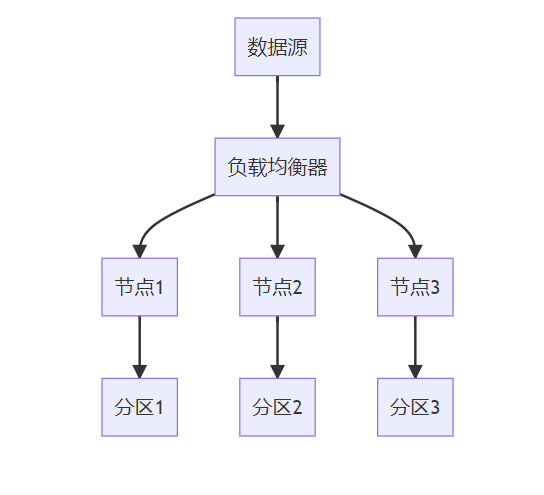 ##### 7.2 查询性能优化 **索引优化** * 确保时间字段有索引 * 为常用标签创建索引 * 定期维护索引统计信息 **查询改写** -- 避免使用函数导致索引失效 SELECT * FROM metrics WHERE date_trunc('hour', time) = '2024-01-01 10:00:00'; -- 改写为范围查询 SELECT * FROM metrics WHERE time >= '2024-01-01 10:00:00' AND time < '2024-01-01 11:00:00'; **结果集缓存** * 缓存频繁查询的结果 * 设置合理的缓存过期时间 * 使用Redis等外部缓存 ##### 7.3 存储空间优化 **数据压缩** * 启用列压缩算法 * 选择合适的压缩级别 * 定期评估压缩效果 **数据生命周期管理** 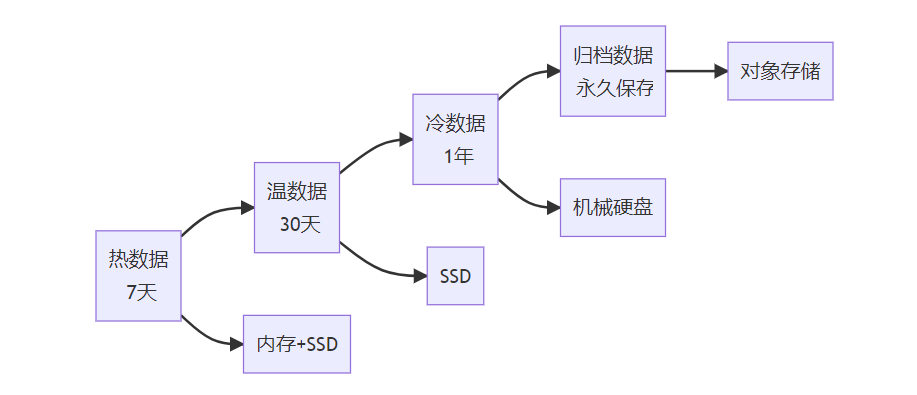 **分区管理** * 按时间自动分区 * 定期清理过期分区 * 压缩合并小分区 * * * #### 第八章:典型应用场景 ##### 8.1 监控与运维 **系统监控架构** 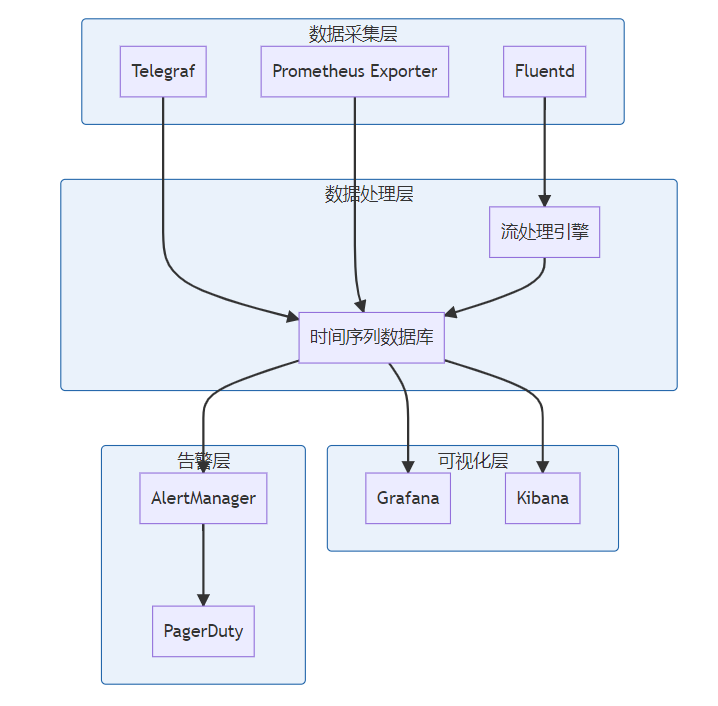 **关键指标监控** * **基础设施指标**:CPU、内存、磁盘、网络 * **应用性能指标**:响应时间、吞吐量、错误率 * **业务指标**:用户活跃度、交易量、转化率 ##### 8.2 物联网数据处理 **物联网数据流架构** 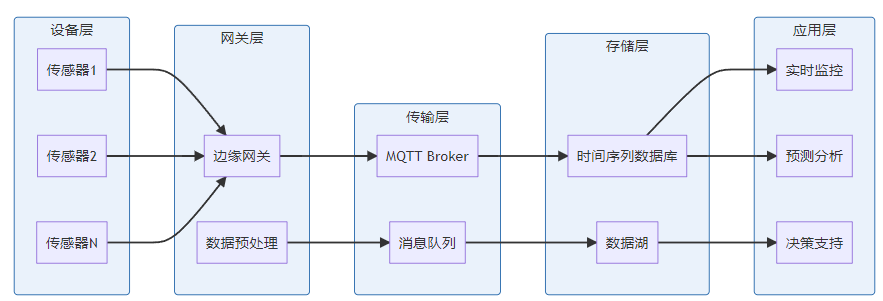 **数据特点** * **高频率**:每秒钟数千到数百万个数据点 * **多样性**:温度、湿度、压力、位置等多种传感器数据 * **时效性**:需要实时处理和响应 ##### 8.3 金融量化分析 **量化交易系统架构** 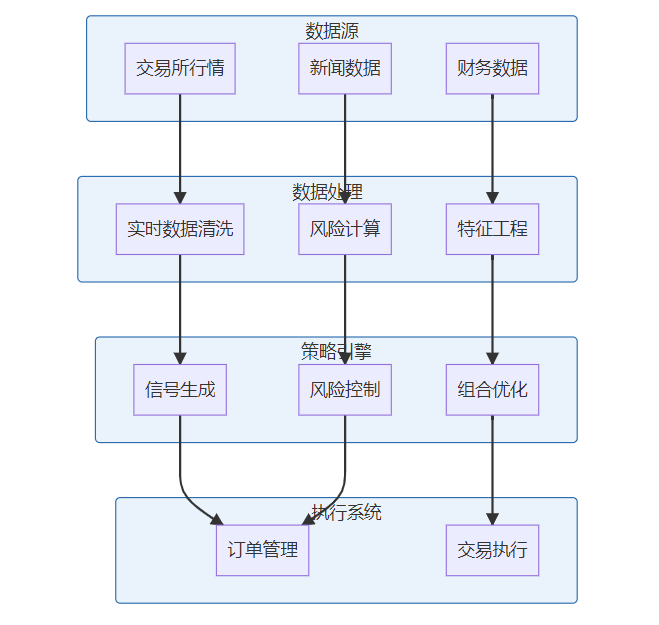 **应用场景** * **高频交易**:毫秒级数据处理和决策 * **风险管理**:实时计算VaR、压力测试 * **算法交易**:基于历史数据的策略回测 * * * #### 第九章:未来发展趋势 ##### 9.1 技术发展方向 **边缘计算集成** 随着物联网和5G技术的发展,时间序列数据处理将向边缘端延伸: * 边缘侧实时处理 * 云边协同架构 * 智能数据压缩和传输 **机器学习融合** 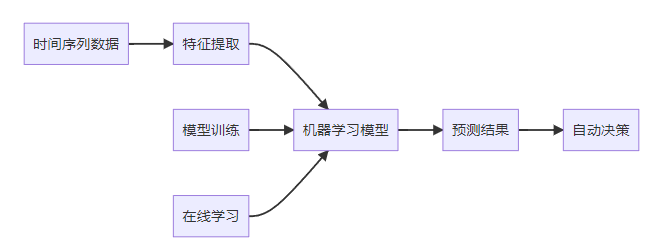 **实时流处理** * [流式计算](https://cloud.tencent.com/product/oceanus?from_column=20065&from=20065)引擎集成 * 实时聚合和分析 * 复杂事件处理(CEP) ##### 9.2 行业应用趋势 **云原生化** * Kubernetes原生支持 * 容器化部署 * 微服务架构 **多云策略** * 跨云数据同步 * [混合云部署](https://cloud.tencent.com/product/cdc?from_column=20065&from=20065) * 灾难恢复 **行业专用方案** * 工业互联网专用TSDB * 金融交易专用系统 * 智慧城市集成平台 ##### 9.3 标准化进程 **数据格式标准化** * 统一的时间序列数据格式 * 跨平台数据交换协议 * 元数据标准规范 **API标准化** * RESTful API规范 * GraphQL查询支持 * gRPC协议标准 **性能评估标准** * 标准化基准测试 * 性能评估指标 * 互操作性测试 * * * #### 第十章:总结与展望 时间序列数据库作为处理时间序列数据的专业工具,在数字化时代发挥着越来越重要的作用。通过本文的深度解析,我们可以得出以下关键结论: ##### 核心价值总结 **技术优势** * **专业化设计**:针对时间序列数据特点优化的存储和查询引擎 * **极致性能**:在写入密集和时间范围查询场景下的卓越表现 * **高效压缩**:通过专用算法实现显著的存储空间节省 * **丰富生态**:完整的监控、可视化和分析工具链 **应用价值** * **运维监控**:提供实时、高精度的系统和应用监控能力 * **物联网**:支持海量设备数据的高效存储和实时分析 * **金融科技**:满足高频交易和风险管理的严格要求 * **工业4.0**:为智能制造提供数据基础设施支撑 ##### 技术选型建议 **小规模场景(数据量 < 1TB)** * 推荐:InfluxDB开源版或TimescaleDB * 优势:部署简单,运维成本低 * 考虑因素:功能完整性、社区活跃度 **中等规模场景(数据量 1TB-10TB)** * 推荐:InfluxDB企业版或云服务 * 优势:性能稳定,技术支持完善 * 考虑因素:成本效益、扩展能力 **大规模场景(数据量 > 10TB)** * 推荐:分布式方案(OpenTSDB、云原生服务) * 优势:水平扩展,高可用性 * 考虑因素:架构复杂度、运维成本 ##### 实施路径规划 **第一阶段:基础建设** 1. 评估现有数据架构和需求 2. 选择合适的时间序列数据库产品 3. 设计数据模型和标签体系 4. 实施POC验证 **第二阶段:生产部署** 1. 建立生产环境集群 2. 迁移历史数据 3. 集成监控和告警系统 4. 建立运维规范 **第三阶段:优化提升** 1. 性能调优和容量规划 2. 数据生命周期管理 3. 高级分析功能开发 4. 与AI/ML平台集成 ##### 发展前景展望 **技术演进方向** * **智能化**:自动调优、智能运维、异常检测 * **实时化**:更低延迟、更高并发、边缘计算 * **标准化**:API标准、数据格式、性能评估 **市场发展趋势** * **市场规模**:预计2025年全球TSDB市场将达到15亿美元 * **应用扩展**:从IT监控扩展到更多业务场景 * **生态完善**:工具链更加丰富,集成更加便捷 **挑战与机遇** * **挑战**:数据隐私保护、跨云互操作、技术人才短缺 * **机遇**:5G+IoT爆发、数字化转型加速、边缘计算兴起 ##### 结语 时间序列数据库技术的发展正处在一个关键节点。随着数字化转型的深入推进和物联网时代的到来,对时间序列数据处理能力的需求将持续增长。企业和开发者应该: 1. **深入理解业务需求**:明确数据规模、性能要求、成本预算 2. **合理选择技术方案**:基于实际需求选择合适的产品和架构 3. **建立完善的数据治理**:从数据建模到生命周期管理的全流程规范 4. **持续关注技术发展**:跟踪新技术趋势,适时升级改进 时间序列数据库不仅是技术工具,更是数字化时代企业竞争力的重要组成部分。掌握和应用好这项技术,将为企业在数据驱动的未来赢得先机。 * * * **参考文献:** 1. Time Series Database Survey and Comparison Study 2. InfluxDB Technical Documentation 3. Prometheus Monitoring Best Practices 4. TimescaleDB Performance Optimization Guide 5. OpenTSDB Architecture and Design Principles
点赞
热门评论
最新评论
匿名用户
+1
-1
·
回复TA
暂无热门评论
相关推荐
阅读更多资讯
热门评论 最新评论
暂无热门评论