星语课程网
【阅读记录-章节6】从零构建大语言模型
来源:本站编辑
2025-02-05 15:05
22
6\. Fine-tuning for classification ---------------------------------- 到目前为止,我们已经完成了 LLM(大语言模型)架构的编写、预训练,并学习了如何将来自外部来源(如 OpenAI)的预训练权重导入到我们的模型中。现在,我们将通过对 LLM 进行微调以适应特定目标任务(例如文本分类)来收获我们的劳动成果。我们具体研究的例子是将文本消息分类为“垃圾短信”或“非垃圾短信”。图 6.1 突出了微调 LLM 的两种主要方式:用于分类的微调(第 8 步)和用于执行指令的微调(第 9 步)。  ### 6.1 Different categories of fine-tuning 语言模型的微调最常见的方式是指令微调和分类微调。指令微调是指使用一组任务及其对应的具体指令对语言模型进行训练,以提高其理解和执行以自然语言提示描述的任务的能力,如图6.2所示。 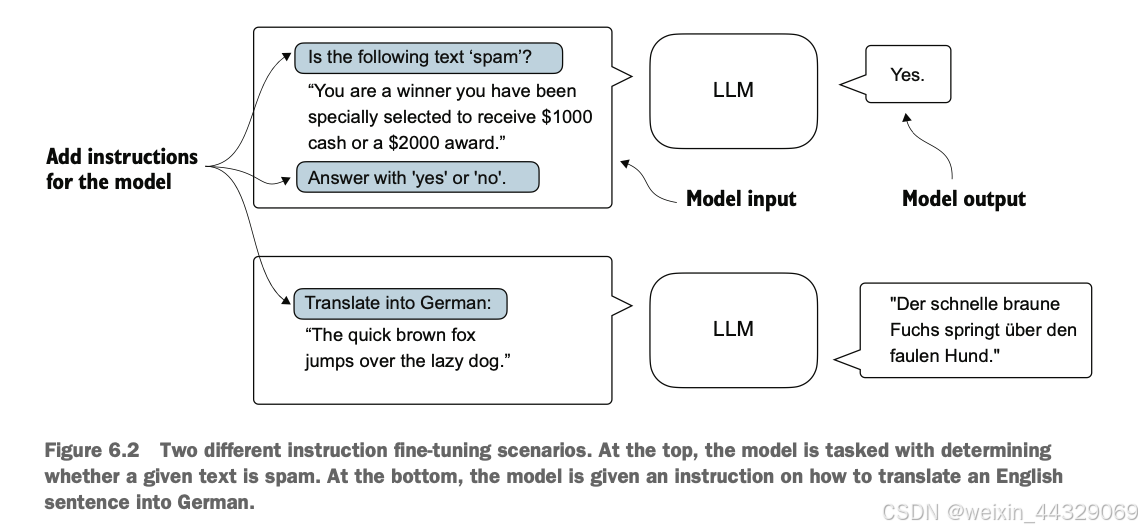 分类微调则是另一种方法,如果你有机器学习背景,可能已经熟悉这一概念。在分类微调中,模型被训练以识别一组特定的类别标签,例如“垃圾邮件”和“非垃圾邮件”。分类任务的应用范围远超LLM和电子邮件过滤,例如从图像中识别不同的植物种类;将新闻文章分类为体育、政治、科技等主题;或者在医学影像中区分良性和恶性肿瘤。 关键的一点是,分类微调的模型只能预测训练中遇到过的类别。例如,它可以判断某些内容是“垃圾邮件”还是“非垃圾邮件”(如图6.3所示),但无法对输入文本作出其他方面的判断。  与图6.3中分类微调模型的局限性不同,指令微调模型通常能够完成更广泛的任务。我们可以将分类微调模型视为高度专业化的模型,而开发一个在各种任务上表现良好的通用模型通常比开发一个专用模型更加困难。 > **如何选择合适的方法** > > * 指令微调可以提高模型基于具体用户指令理解和生成响应的能力。它更适合需要处理多种任务的模型,尤其是那些基于复杂用户指令的任务,提高了灵活性和交互质量。分类微调则更适合需要将数据精准分类为预定义类别的项目,例如情感分析或垃圾邮件检测。 > * 虽然指令微调更加通用,但它需要更大的数据集和更多的计算资源来开发能够胜任多种任务的模型。相比之下,分类微调所需的数据和计算资源较少,但其用途局限于模型已训练过的特定类别。 ### 6.2 Preparing the dataset 我们将对之前实现并预训练的GPT模型进行修改和分类微调。首先,我们需要下载并准备数据集,如图6.4所示。为了提供一个直观且有用的分类微调示例,我们将使用一个包含垃圾短信和非垃圾短信的文本消息数据集。 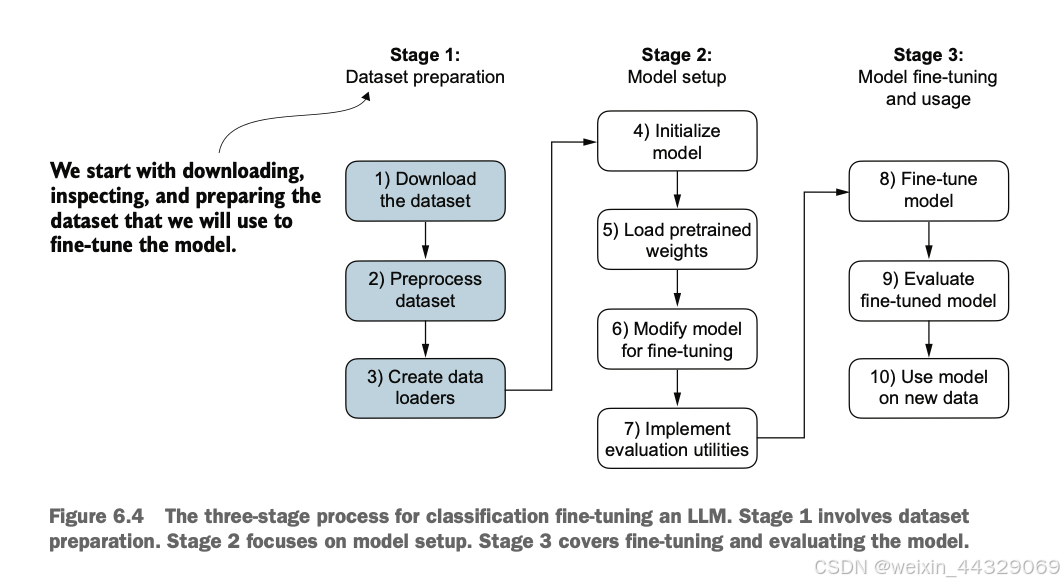 > **注意**:这里的文本消息通常是指通过手机发送的消息,而非电子邮件。然而,同样的步骤也适用于电子邮件分类。感兴趣的读者可以在附录B中找到电子邮件垃圾分类数据集的链接。 #### 第一步:下载并解压数据集 import urllib.request import zipfile import os from pathlib import Path url = "https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip" zip_path = "sms_spam_collection.zip" extracted_path = "sms_spam_collection" data_file_path = Path(extracted_path) / "SMSSpamCollection.tsv" def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path): if data_file_path.exists(): print(f"{data_file_path} already exists. Skipping download and extraction.") return with urllib.request.urlopen(url) as response: with open(zip_path, "wb") as out_file: out_file.write(response.read()) with zipfile.ZipFile(zip_path, "r") as zip_ref: zip_ref.extractall(extracted_path) original_file_path = Path(extracted_path) / "SMSSpamCollection" os.rename(original_file_path, data_file_path) print(f"File downloaded and saved as {data_file_path}") download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path) 运行上述代码后,数据集将保存为一个制表符分隔的文本文件`SMSSpamCollection.tsv`,位于`sms_spam_collection`文件夹中。我们可以通过以下代码将其加载到Pandas数据框中: import pandas as pd df = pd.read_csv( data_file_path, sep="\t", header=None, names=["Label", "Text"] ) df 在Jupyter Notebook中运行此代码将渲染数据框,或者可以通过`print(df)`来查看结果。图6.5展示了垃圾短信数据集的数据框。  #### 第二步:检查类别标签分布 运行以下代码: print(df["Label"].value_counts()) 执行上述代码后,我们可以发现数据集中“非垃圾”(`ham`)远多于“垃圾”(`spam`): Label ham 4825 spam 747 Name: count, dtype: int64 为了简单起见,同时为了便于使用较小的数据集(这将加快LLM的微调速度),我们选择对数据集进行欠采样,使每类包含747个实例。 > **注意**:处理类别不平衡还有许多其他方法,但这些内容超出了本书范围。读者可以在附录B中找到关于处理数据不平衡方法的更多信息。 #### 第三步:创建平衡数据集 def create_balanced_dataset(df): num_spam = df[df["Label"] == "spam"].shape[0] ham_subset = df[df["Label"] == "ham"].sample( num_spam, random_state=123 ) balanced_df = pd.concat([ ham_subset, df[df["Label"] == "spam"] ]) return balanced_df balanced_df = create_balanced_dataset(df) print(balanced_df["Label"].value_counts()) 执行上述代码后,我们可以看到数据集中垃圾短信和非垃圾短信的数量相等: Label ham 747 spam 747 Name: count, dtype: int64 接下来,我们将字符串标签“ham”和“spam”转换为整数标签0和1: balanced_df["Label"] = balanced_df["Label"].map({"ham": 0, "spam": 1}) 这个过程类似于将文本转换为令牌ID,但这里我们只处理两个令牌ID:0和1。 * * * #### 第四步:数据集拆分 接下来,我们创建一个`random_split`函数,将数据集分为三部分:70%用于训练,10%用于验证,20%用于测试。这些比例在机器学习中非常常见,用于训练、调整和评估模型。 def random_split(df, train_frac, validation_frac): df = df.sample( frac=1, random_state=123 ).reset_index(drop=True) train_end = int(len(df) * train_frac) validation_end = train_end + int(len(df) * validation_frac) train_df = df[:train_end] validation_df = df[train_end:validation_end] test_df = df[validation_end:] return train_df, validation_df, test_df train_df, validation_df, test_df = random_split( balanced_df, 0.7, 0.1 ) 接着,我们将数据集保存为CSV文件,以便后续使用: train_df.to_csv("train.csv", index=None) validation_df.to_csv("validation.csv", index=None) test_df.to_csv("test.csv", index=None) 到目前为止,我们已经完成了数据集的下载、平衡处理,并将其拆分为训练和评估子集。接下来,我们将设置PyTorch数据加载器,用于训练模型。 ### 6.3 Creating data loaders 我们将开发与之前处理文本数据时概念上相似的 PyTorch 数据加载器。在之前的实现中,我们使用滑动窗口技术生成了统一大小的文本块,并将其分组为批次以提高模型训练效率。每个文本块作为一个独立的训练实例。然而,现在我们使用的是包含长度不同的短信的数据集。要将这些短信分批处理,我们有两种主要选择: * **选项1**:将所有短信截断为数据集中或批次中最短短信的长度。 * **选项2**:将所有短信填充到数据集中或批次中最长短信的长度。 第一个选项计算成本较低,但如果较短的短信远小于平均长度或最长长度,可能会导致显著的信息丢失,从而降低模型性能。因此,我们选择第二个选项,它可以保留所有短信的完整内容。 为实现批处理(将所有短信填充到数据集中最长短信的长度),我们在较短的短信中添加填充标记(padding token)。我们使用`"<|endoftext|>"`作为填充标记。 然而,我们并不直接在每条短信后添加字符串`"<|endoftext|>"`,而是向编码后的文本消息添加对应的标记ID。例如,标记ID`50256`对应`"<|endoftext|>"`。我们可以通过使用`tiktoken`包的GPT-2分词器验证标记ID是否正确: import tiktoken tokenizer = tiktoken.get_encoding("gpt2") print(tokenizer.encode("<|endoftext|>", allowed_special={"<|endoftext|>"})) 执行上述代码会返回`[50256]`,证明`50256`确实是`"<|endoftext|>"`的标记ID。  #### 创建 PyTorch Dataset 在实例化数据加载器之前,我们需要实现一个 PyTorch Dataset,用于指定如何加载和处理数据。为此,我们定义了一个 `SpamDataset` 类,该类的功能包括: * 确定训练数据集中最长序列的长度。 * 对短信进行编码。 * 使用填充标记将其他序列填充到最长序列的长度。 ##### 设置 PyTorch Dataset 类 import torch from torch.utils.data import Dataset class SpamDataset(Dataset): def __init__(self, csv_file, tokenizer, max_length=None, pad_token_id=50256): self.data = pd.read_csv(csv_file) # 对文本进行预编码 self.encoded_texts = [ tokenizer.encode(text) for text in self.data["Text"] ] if max_length is None: self.max_length = self._longest_encoded_length() else: self.max_length = max_length # 截断超出 max_length 的序列 self.encoded_texts = [ encoded_text[:self.max_length] for encoded_text in self.encoded_texts ] # 填充序列到最长长度 self.encoded_texts = [ encoded_text + [pad_token_id] * (self.max_length - len(encoded_text)) for encoded_text in self.encoded_texts ] def __getitem__(self, index): encoded = self.encoded_texts[index] label = self.data.iloc[index]["Label"] return ( torch.tensor(encoded, dtype=torch.long), torch.tensor(label, dtype=torch.long) ) def __len__(self): return len(self.data) def _longest_encoded_length(self): max_length = 0 for encoded_text in self.encoded_texts: encoded_length = len(encoded_text) if encoded_length > max_length: max_length = encoded_length return max_length ##### 工作原理 `SpamDataset` 类从我们之前创建的 CSV 文件中加载数据,使用 `tiktoken` 提供的 GPT-2 分词器对文本进行标记化,并填充或截断序列以统一长度。这确保每个输入张量的大小一致,从而可以创建用于训练的数据加载器。 我们可以这样初始化训练数据集: train_dataset = SpamDataset( csv_file="train.csv", max_length=None, tokenizer=tokenizer ) 最长序列的长度存储在数据集的 `max_length` 属性中。如果想查看最长序列的令牌数量,可以运行以下代码: print(train_dataset.max_length) 输出为`120`,说明最长序列不超过120个标记。模型支持的上下文长度限制为1024个标记。如果数据集中有更长的文本,可以在创建训练数据集时传递 `max_length=1024`。 接下来,我们对验证集和测试集进行填充,以匹配训练集中最长序列的长度: val_dataset = SpamDataset( csv_file="validation.csv", max_length=train_dataset.max_length, tokenizer=tokenizer ) test_dataset = SpamDataset( csv_file="test.csv", max_length=train_dataset.max_length, tokenizer=tokenizer ) 使用这些数据集作为输入,我们可以像处理文本数据时一样实例化数据加载器。然而,在这种情况下,目标值表示的是类别标签,而不是文本中的下一个标记。例如,如果我们选择批量大小为8,每个批次将包含8个长度为120的训练样本及其对应的类别标签,如图6.7所示。  以下代码创建了用于加载训练集、验证集和测试集的 PyTorch 数据加载器,这些加载器以批量大小为8的形式加载文本消息及其标签。 ##### 创建 PyTorch 数据加载器 from torch.utils.data import DataLoader num_workers = 0 batch_size = 8 torch.manual_seed(123) train_loader = DataLoader( dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, ) val_loader = DataLoader( dataset=val_dataset, batch_size=batch_size, num_workers=num_workers, drop_last=False, ) test_loader = DataLoader( dataset=test_dataset, batch_size=batch_size, num_workers=num_workers, drop_last=False, ) 为验证数据加载器是否返回预期大小的批次,可以遍历训练加载器并打印最后一个批次的张量维度: for input_batch, target_batch in train_loader: pass print("Input batch dimensions:", input_batch.shape) print("Label batch dimensions", target_batch.shape) 输出为: Input batch dimensions: torch.Size([8, 120]) Label batch dimensions: torch.Size([8]) 这表明每个输入批次包含8条训练示例,每条包含120个标记,标签张量存储8条训练示例的类别标签。 最后,打印每个数据集的总批次数量以了解数据集的大小: print(f"{len(train_loader)} training batches") print(f"{len(val_loader)} validation batches") print(f"{len(test_loader)} test batches") 输出为: 130 training batches 19 validation batches 38 test batches 数据准备完成后,我们可以着手准备模型以进行微调。 ### 6.4 Initializing a model with pretrained weights 我们需要为模型的分类微调做好准备,以识别垃圾短信。我们首先初始化预训练模型,如图 6.8 所示。  为了开始模型准备过程,我们使用与在无标签数据上进行预训练时相同的配置: CHOOSE_MODEL = "gpt2-small (124M)" INPUT_PROMPT = "Every effort moves" BASE_CONFIG = { "vocab_size": 50257, # 词汇表大小 "context_length": 1024, # 上下文长度 "drop_rate": 0.0, # Dropout 率 "qkv_bias": True # Query-Key-Value 偏置 } model_configs = { "gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12}, "gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16}, "gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20}, "gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25}, } BASE_CONFIG.update(model_configs[CHOOSE_MODEL]) 接下来,我们从 `gpt_download.py` 文件中导入 `download_and_load_gpt2` 函数,并复用第 5 章中的 `GPTModel` 类和 `load_weights_into_gpt` 函数,将下载的权重加载到 GPT 模型中。 #### 加载预训练的 GPT 模型 from gpt_download import download_and_load_gpt2 from chapter05 import GPTModel, load_weights_into_gpt model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")") settings, params = download_and_load_gpt2( model_size=model_size, models_dir="gpt2" ) model = GPTModel(BASE_CONFIG) load_weights_into_gpt(model, params) model.eval() 将模型权重加载到 `GPTModel` 后,我们可以复用第 4 和 5 章的文本生成工具函数,来验证模型是否能够生成连贯的文本,确保权重加载正确: from chapter04 import generate_text_simple from chapter05 import text_to_token_ids, token_ids_to_text text_1 = "Every effort moves you" token_ids = generate_text_simple( model=model, idx=text_to_token_ids(text_1, tokenizer), max_new_tokens=15, context_size=BASE_CONFIG["context_length"] ) print(token_ids_to_text(token_ids, tokenizer)) 输出: Every effort moves you forward. The first step is to understand the importance of your work 从输出结果可以看出,模型生成了连贯的文本,说明权重已正确加载。 #### 检查模型是否能识别垃圾短信 在对模型进行垃圾短信分类的微调之前,我们可以通过指令提示来查看模型是否能够直接分类垃圾短信: text_2 = ( "Is the following text 'spam'? Answer with 'yes' or 'no':" " 'You are a winner you have been specially" " selected to receive $1000 cash or a $2000 award.'" ) token_ids = generate_text_simple( model=model, idx=text_to_token_ids(text_2, tokenizer), max_new_tokens=23, context_size=BASE_CONFIG["context_length"] ) print(token_ids_to_text(token_ids, tokenizer)) 输出: Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.' The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner 从输出可以看出,模型难以按照指令进行操作。这是预期的结果,因为模型仅经过预训练,尚未进行指令微调。 由于模型尚未进行指令微调,我们需要对模型进行分类微调以适应垃圾短信分类任务。这将是接下来的重点步骤。 ### 6.5 Adding a classification head 我们必须对预训练的 LLM 进行修改,以便为分类微调做准备。具体来说,我们将原始的输出层(将隐藏表示映射到大小为 50,257 的词汇表)替换为一个更小的输出层,该输出层将隐藏表示映射到两个类别:0(“非垃圾”)和 1(“垃圾”),如图 6.9 所示。除了更换输出层外,其余模型保持不变。 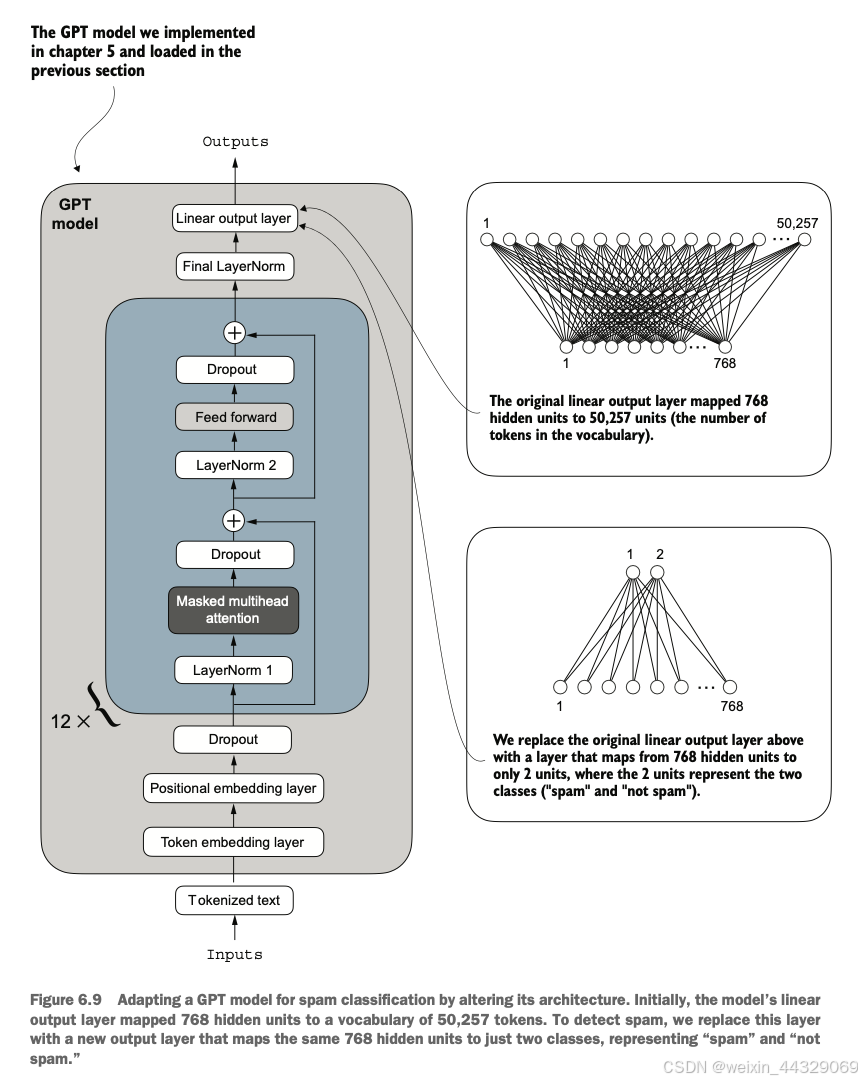 > 输出层节点 > > * 尽管我们可以技术上使用一个单一的输出节点(因为这是一个二分类任务),但这需要修改损失函数(相关内容参见《Losses Learned—Optimizing Negative Log-Likelihood and Cross-Entropy in PyTorch》 [https://mng.bz/NRZ2](https://mng.bz/NRZ2))。因此,我们选择一种更通用的方法:输出节点的数量等于类别数量。例如,对于一个三分类问题(如将新闻文章分类为“科技”、“体育”或“政治”),我们将使用三个输出节点,以此类推。 在进行图 6.9 所示的修改之前,我们可以通过 `print(model)` 打印模型的架构,输出如下: GPTModel( (tok_emb): Embedding(50257, 768) (pos_emb): Embedding(1024, 768) (drop_emb): Dropout(p=0.0, inplace=False) (trf_blocks): Sequential( ... (11): TransformerBlock( (att): MultiHeadAttention( (W_query): Linear(in_features=768, out_features=768, bias=True) (W_key): Linear(in_features=768, out_features=768, bias=True) (W_value): Linear(in_features=768, out_features=768, bias=True) (out_proj): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.0, inplace=False) ) ) (ff): FeedForward( (layers): Sequential( (0): Linear(in_features=768, out_features=3072, bias=True) (1): GELU() (2): Linear(in_features=3072, out_features=768, bias=True) ) (norm1): LayerNorm() (norm2): LayerNorm() (drop_resid): Dropout(p=0.0, inplace=False) ) ) (final_norm): LayerNorm() (out_head): Linear(in_features=768, out_features=50257, bias=False) ) 输出清晰地展示了 GPT 模型的架构(如第 4 章所述)。`GPTModel` 包括嵌入层(`tok_emb` 和 `pos_emb`),随后是 12 个相同的 Transformer 块(为了简洁,仅展示最后一个块),最终是一个 `LayerNorm` 和输出层(`out_head`)。 接下来,我们将 `out_head` 替换为一个新的输出层(参见图 6.9),并对其进行微调。 * * * > **微调选择:只调整部分层还是调整所有层?** > > * 由于我们从预训练模型开始,因此不需要微调模型的所有层。在基于神经网络的语言模型中,底层通常捕获适用于广泛任务和数据集的基本语言结构和语义。因而,仅微调靠近输出层的最后几层(捕获更细致的语言模式和任务特定特征)通常足以让模型适应新任务。 > * 这种方法的另一个好处是,只微调少量层在计算上更高效。更多关于微调哪些层的实验和信息可以参见附录 B。 为了准备分类微调,我们首先冻结模型,使所有层变为不可训练: for param in model.parameters(): param.requires_grad = False 然后,我们将输出层(`model.out_head`)替换为一个新的输出层,其将输入映射到两个维度(类别数为 2): torch.manual_seed(123) num_classes = 2 model.out_head = torch.nn.Linear( in_features=BASE_CONFIG["emb_dim"], # 嵌入维度,gpt2-small 为 768 out_features=num_classes ) 为了保持代码通用,我们使用了 `BASE_CONFIG["emb_dim"]`,它在 `gpt2-small (124M)` 模型中等于 768。这使得代码也能适用于更大的 GPT-2 模型变体。 新的 `model.out_head` 输出层的 `requires_grad` 属性默认设置为 `True`,这意味着它是模型中唯一会在训练中更新的层。 * * * #### 使最后一个 Transformer 块和 `LayerNorm` 可训练  尽管训练新增的输出层已经足够,但实验表明,微调额外的层可以显著提高模型的预测性能(详见附录 B)。因此,我们还配置最后一个 Transformer 块和连接该块与输出层的最终 `LayerNorm` 模块为可训练状态: for param in model.trf_blocks[-1].parameters(): param.requires_grad = True for param in model.final_norm.parameters(): param.requires_grad = True 尽管我们添加了新的输出层,并标记了某些层是否可训练,仍可以像以前一样使用该模型。例如,我们可以向模型输入一段示例文本并检查其输出: inputs = tokenizer.encode("Do you have time") inputs = torch.tensor(inputs).unsqueeze(0) print("Inputs:", inputs) print("Inputs dimensions:", inputs.shape) 输出: Inputs: tensor([[5211, 345, 423, 640]]) Inputs dimensions: torch.Size([1, 4]) 随后,将编码后的 token ID 传递给模型: with torch.no_grad(): outputs = model(inputs) print("Outputs:\n", outputs) print("Outputs dimensions:", outputs.shape) 输出: Outputs: tensor([[[-1.5854, 0.9904], [-3.7235, 7.4548], [-2.2661, 6.6049], [-3.5983, 3.9902]]]) Outputs dimensions: torch.Size([1, 4, 2]) 注意,输出的张量维度为 `[1, 4, 2]`,而不是之前的 `[1, 4, 50257]`。输出的行数与输入 token 数相同(本例为 4),但每行的嵌入维度现在是 2(类别数)而非 50,257(词汇表大小)。 * * * #### 为什么关注最后一个输出 token? 请记住,我们的目标是对模型进行微调,以输出一个类别标签,指示输入是“垃圾邮件”还是“非垃圾邮件”。我们不需要对所有四个输出行进行微调,而是可以专注于一个输出标记。具体来说,我们将关注最后一行,对应于最后一个输出标记,如图 6.11 所示 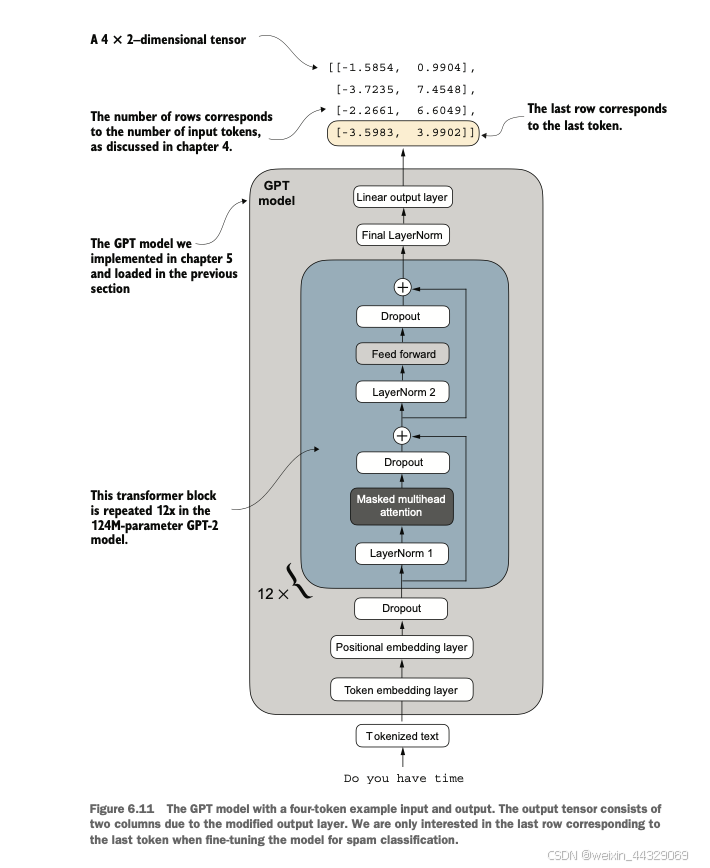 我们可以使用以下代码提取最后一个输出 token: print("Last output token:", outputs[:, -1, :]) 输出: Last output token: tensor([[-3.5983, 3.9902]]) 我们仍然需要将输出的值转换为类别标签预测。但首先,让我们了解为什么特别关注最后一个输出标记。 我们已经探讨了注意力机制,它在每个输入标记和其他输入标记之间建立了关联,以及因果注意力掩码(causal attention mask)的概念,这在类似 GPT 的模型中被广泛使用(参见第 3 章)。这种掩码限制了每个标记的关注范围,使其只能关注当前标记及其之前的标记,确保每个标记只受到自身和之前标记的影响,如图 6.12 所示。  基于图 6.12 所示的因果注意力掩码设置,序列中的最后一个标记累积了最多的信息,因为它是唯一一个可以访问所有先前标记数据的标记。因此,在垃圾邮件分类任务中,我们在微调过程中专注于这个最后的标记。 现在,我们准备将最后一个标记的输出转换为类别标签预测,并计算模型的初始预测准确率。随后,我们将对模型进行垃圾邮件分类任务的微调。 ### 6.6 Calculating the classification loss and accuracy 在对模型进行微调之前,还有一个小任务需要完成:实现微调过程中使用的模型评估函数,如图 6.13 所示。  在实现评估工具之前,让我们简单讨论一下如何将模型的输出转换为类别标签预测。此前,我们通过将 50,257 维的输出使用 softmax 函数转换为概率,然后通过 argmax 函数返回最高概率的位置来计算 LLM 生成的下一个标记的 token ID。这里我们使用相同的方法来计算模型是否预测给定输入为“垃圾邮件”或“非垃圾邮件”,如图 6.14 所示。唯一的区别是,我们处理的是二维输出,而不是 50,257 维的输出。  让我们通过一个具体的例子来看最后一个输出标记: print("Last output token:", outputs[:, -1, :]) 对应于最后一个标记的张量值是: Last output token: tensor([[-3.5983, 3.9902]]) 我们可以通过以下代码获得类别标签: probas = torch.softmax(outputs[:, -1, :], dim=-1) label = torch.argmax(probas) print("Class label:", label.item()) 在这种情况下,代码返回 `1`,这意味着模型预测输入文本为“垃圾邮件”。在这里使用 softmax 函数是可选的,因为输出中最大的值直接对应于最高的概率分数。因此,可以不使用 softmax 来简化代码: logits = outputs[:, -1, :] label = torch.argmax(logits) print("Class label:", label.item()) 这个方法可以用来计算分类准确率,即整个数据集中正确预测的百分比。 为了确定分类准确率,我们对数据集中的所有示例应用基于 argmax 的预测代码,并通过定义 `calc_accuracy_loader` 函数计算正确预测的比例。 ##### 计算分类准确率 def calc_accuracy_loader(data_loader, model, device, num_batches=None): model.eval() correct_predictions, num_examples = 0, 0 if num_batches is None: num_batches = len(data_loader) else: num_batches = min(num_batches, len(data_loader)) for i, (input_batch, target_batch) in enumerate(data_loader): if i < num_batches: input_batch = input_batch.to(device) target_batch = target_batch.to(device) with torch.no_grad(): logits = model(input_batch)[:, -1, :] # 取最后一个标记的 logits predicted_labels = torch.argmax(logits, dim=-1) # 预测标签 num_examples += predicted_labels.shape[0] correct_predictions += ( (predicted_labels == target_batch).sum().item() ) else: break return correct_predictions / num_examples 使用该函数可以高效地估算各种数据集上的分类准确率,默认处理 10 个批次: device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) torch.manual_seed(123) train_accuracy = calc_accuracy_loader( train_loader, model, device, num_batches=10 ) val_accuracy = calc_accuracy_loader( val_loader, model, device, num_batches=10 ) test_accuracy = calc_accuracy_loader( test_loader, model, device, num_batches=10 ) print(f"Training accuracy: {train_accuracy*100:.2f}%") print(f"Validation accuracy: {val_accuracy*100:.2f}%") print(f"Test accuracy: {test_accuracy*100:.2f}%") 通过设备设置,模型会自动在支持 Nvidia CUDA 的 GPU 上运行,否则将在 CPU 上运行。输出如下: Training accuracy: 46.25% Validation accuracy: 45.00% Test accuracy: 48.75% 正如我们所见,预测准确率接近随机预测的水平(本例中为 50%)。为了提高预测准确率,我们需要对模型进行微调。 * * * #### 定义分类损失函数 在开始微调模型之前,我们需要定义训练过程中优化的损失函数。我们的目标是最大化模型的垃圾邮件分类准确率,这意味着模型应该输出正确的类别标签:0(非垃圾邮件)或 1(垃圾邮件)。 由于分类准确率不是可微函数,我们使用交叉熵损失作为替代,以间接最大化准确率。为此,`calc_loss_batch` 函数保持不变,但有一个调整:我们只优化最后一个标记的输出(`model(input_batch)[:, -1, :]`),而不是所有标记的输出(`model(input_batch)`): def calc_loss_batch(input_batch, target_batch, model, device): input_batch = input_batch.to(device) target_batch = target_batch.to(device) logits = model(input_batch)[:, -1, :] # 取最后一个标记的 logits loss = torch.nn.functional.cross_entropy(logits, target_batch) return loss 我们使用 `calc_loss_batch` 函数计算从先前定义的数据加载器中获取的单个批次的损失。为了计算整个数据加载器的所有批次的损失,我们像以前一样定义 `calc_loss_loader` 函数。 ##### 计算分类损失 def calc_loss_loader(data_loader, model, device, num_batches=None): total_loss = 0. if len(data_loader) == 0: return float("nan") elif num_batches is None: num_batches = len(data_loader) else: num_batches = min(num_batches, len(data_loader)) for i, (input_batch, target_batch) in enumerate(data_loader): if i < num_batches: loss = calc_loss_batch( input_batch, target_batch, model, device ) total_loss += loss.item() else: break return total_loss / num_batches 与计算训练准确率类似,我们现在计算每个数据集的初始损失: with torch.no_grad(): train_loss = calc_loss_loader( train_loader, model, device, num_batches=5 ) val_loss = calc_loss_loader(val_loader, model, device, num_batches=5) test_loss = calc_loss_loader(test_loader, model, device, num_batches=5) print(f"Training loss: {train_loss:.3f}") print(f"Validation loss: {val_loss:.3f}") print(f"Test loss: {test_loss:.3f}") 初始损失值: Training loss: 2.453 Validation loss: 2.583 Test loss: 2.322 * * * 接下来,我们将实现一个训练函数,通过最小化训练集的损失来微调模型。最小化训练集损失将有助于提高分类准确率,这是我们的最终目标。 ### 6.7 Fine-tuning the model on supervised data 我们必须定义并使用训练函数来对预训练的 LLM 进行微调,并提高其垃圾邮件分类准确率。训练循环,如图 6.15 所示,是我们在预训练时使用的相同训练循环;唯一的区别是我们计算的是分类准确率,而不是生成示例文本来评估模型。  实现图 6.15 中概念的训练函数与我们用于预训练模型的 `train_model_simple` 函数非常相似。唯一的两点区别是,现在我们追踪的是看到的训练示例数量(`examples_seen`),而不是标记数量,并且我们在每个 epoch 后计算准确率,而不是打印示例文本。 ##### 微调模型以分类垃圾邮件 # 初始化用于追踪损失和已见示例的列表 def train_classifier_simple( model, train_loader, val_loader, optimizer, device, num_epochs, eval_freq, eval_iter): train_losses, val_losses, train_accs, val_accs = [], [], [], [] examples_seen, global_step = 0, -1 # 主训练循环 for epoch in range(num_epochs): model.train() # 将模型设置为训练模式 # 重置损失梯度 for input_batch, target_batch in train_loader: optimizer.zero_grad() loss = calc_loss_batch(input_batch, target_batch, model, device) loss.backward() optimizer.step() examples_seen += input_batch.shape[0] global_step += 1 # 可选评估步骤 if global_step % eval_freq == 0: train_loss, val_loss = evaluate_model( model, train_loader, val_loader, device, eval_iter) train_losses.append(train_loss) val_losses.append(val_loss) print(f"Ep {epoch+1} (Step {global_step:06d}): " f"Train loss {train_loss:.3f}, " f"Val loss {val_loss:.3f}") # 计算准确率 train_accuracy = calc_accuracy_loader( train_loader, model, device, num_batches=eval_iter ) val_accuracy = calc_accuracy_loader( val_loader, model, device, num_batches=eval_iter ) print(f"Training accuracy: {train_accuracy*100:.2f}% | ", end="") print(f"Validation accuracy: {val_accuracy*100:.2f}%") train_accs.append(train_accuracy) val_accs.append(val_accuracy) return train_losses, val_losses, train_accs, val_accs, examples_seen `evaluate_model` 函数与我们用于预训练时使用的完全相同: def evaluate_model(model, train_loader, val_loader, device, eval_iter): model.eval() with torch.no_grad(): train_loss = calc_loss_loader( train_loader, model, device, num_batches=eval_iter ) val_loss = calc_loss_loader( val_loader, model, device, num_batches=eval_iter ) model.train() return train_loss, val_loss 接下来,我们初始化优化器,设置训练 epoch 数,并使用 `train_classifier_simple` 函数开始训练。训练大约需要 6 分钟时间(在 M3 MacBook Air 上),在 V100 或 A100 GPU 上则需要不到半分钟时间: import time start_time = time.time() torch.manual_seed(123) optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5, weight_decay=0.1) num_epochs = 5 train_losses, val_losses, train_accs, val_accs, examples_seen = \ train_classifier_simple( model, train_loader, val_loader, optimizer, device, num_epochs=num_epochs, eval_freq=50, eval_iter=5 ) end_time = time.time() execution_time_minutes = (end_time - start_time) / 60 print(f"Training completed in {execution_time_minutes:.2f} minutes.") 在训练过程中,我们会看到如下输出: Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392 Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637 Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557 Training accuracy: 70.00% | Validation accuracy: 72.50% Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489 Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397 Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353 Training accuracy: 82.50% | Validation accuracy: 85.00% Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320 Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306 Training accuracy: 90.00% | Validation accuracy: 90.00% Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200 Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132 Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137 Training accuracy: 100.00% | Validation accuracy: 97.50% Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143 Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074 Training accuracy: 100.00% | Validation accuracy: 97.50% Training completed in 5.65 minutes. 接下来,我们使用 Matplotlib 绘制训练集和验证集的损失函数。 ##### 绘制分类损失 import matplotlib.pyplot as plt def plot_values( epochs_seen, examples_seen, train_values, val_values, label="loss"): fig, ax1 = plt.subplots(figsize=(5, 3)) ax1.plot(epochs_seen, train_values, label=f"Training {label}") ax1.plot( epochs_seen, val_values, linestyle="-.", label=f"Validation {label}" ) ax1.set_xlabel("Epochs") ax1.set_ylabel(label.capitalize()) ax1.legend() ax2 = ax1.twiny() ax2.plot(examples_seen, train_values, alpha=0) ax2.set_xlabel("Examples seen") fig.tight_layout() plt.savefig(f"{label}-plot.pdf") plt.show() epochs_tensor = torch.linspace(0, num_epochs, len(train_losses)) examples_seen_tensor = torch.linspace(0, examples_seen, len(train_losses)) plot_values(epochs_tensor, examples_seen_tensor, train_losses, val_losses) 图 6.16 展示了结果的损失曲线。 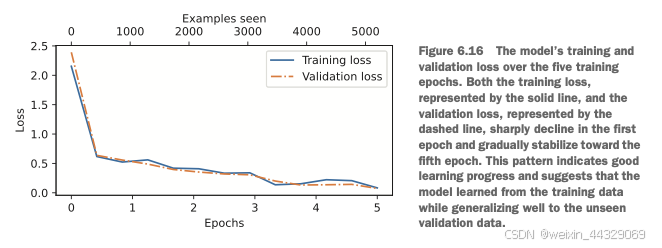 正如我们从图 6.16 中明显的下降趋势中看到的那样,模型在训练数据上学习得很好,并且几乎没有过拟合的迹象;也就是说,训练集和验证集的损失之间没有明显的差距。 之前在启动训练时,我们将 epoch 数量设置为 5。epoch 的数量取决于数据集和任务的难度,没有通用的解决方案或推荐,尽管五个 epoch 通常是一个不错的起点。如果模型在前几个 epoch 后发生过拟合(如损失图所示,见图 6.16),则可能需要减少 epoch 数量。相反,如果趋势线表明验证损失随着进一步训练可以改善,则应该增加 epoch 数量。在这个具体的案例中,五个 epoch 是合理的,因为没有出现早期过拟合的迹象,并且验证损失接近 0。 使用相同的 `plot_values` 函数,现在让我们绘制分类准确率: epochs_tensor = torch.linspace(0, num_epochs, len(train_accs)) examples_seen_tensor = torch.linspace(0, examples_seen, len(train_accs)) plot_values( epochs_tensor, examples_seen_tensor, train_accs, val_accs, label="accuracy" ) 图 6.17 展示了结果的准确率曲线。模型在第 4 和第 5 个 epoch 后实现了相对较高的训练和验证准确率。值得注意的是,我们在使用 `train_classifier_simple` 函数时之前将 `eval_iter=5` 设置为 5,这意味着我们在训练期间对训练和验证性能的估算仅基于 5 个批次,以提高训练效率。  现在,我们必须通过运行以下代码来计算整个数据集上训练、验证和测试集的性能指标,这次不定义 `eval_iter` 值: train_accuracy = calc_accuracy_loader(train_loader, model, device) val_accuracy = calc_accuracy_loader(val_loader, model, device) test_accuracy = calc_accuracy_loader(test_loader, model, device) print(f"Training accuracy: {train_accuracy*100:.2f}%") print(f"Validation accuracy: {val_accuracy*100:.2f}%") print(f"Test accuracy: {test_accuracy*100:.2f}%") 结果准确率: Training accuracy: 97.21% Validation accuracy: 97.32% Test accuracy: 95.67% 训练集和测试集的性能几乎完全相同。训练集和测试集准确率之间的轻微差异表明训练数据的过拟合非常小。通常,验证集的准确率会略高于测试集的准确率,因为模型开发过程中通常会调整超参数,以便在验证集上表现良好,而这种调整可能并不总是能有效地推广到测试集上。这种情况很常见,但通过调整模型设置(例如增加 dropout 率 `drop_rate` 或优化器配置中的 `weight_decay` 参数),可以最大限度地减少这种差距。 ### 6.8 Using the LLM as a spam classifier 在完成模型的微调和评估后,我们现在可以开始分类垃圾短信(见图 6.18)。  让我们使用我们微调后的基于 GPT 的垃圾邮件分类模型。以下 `classify_review` 函数遵循类似于我们在先前实现的 `SpamDataset` 中使用的数据预处理步骤。然后,在将文本处理为 token ID 后,该函数使用模型预测一个整数类别标签,类似于我们在第 6.6 节中实现的内容,并返回相应的类别名称。 ##### 使用模型分类新文本 def classify_review( text, model, tokenizer, device, max_length=None, pad_token_id=50256): model.eval() # 设置模型为评估模式 # 准备输入 input_ids = tokenizer.encode(text) supported_context_length = model.pos_emb.weight.shape[1] # 如果序列太长,则截断 input_ids = input_ids[:min( max_length, supported_context_length )] # 填充序列到最大长度 input_ids += [pad_token_id] * (max_length - len(input_ids)) input_tensor = torch.tensor( input_ids, device=device ).unsqueeze(0) # 添加批次维度 with torch.no_grad(): # 在不计算梯度的情况下进行推理 logits = model(input_tensor)[:, -1, :] predicted_label = torch.argmax(logits, dim=-1).item() return "spam" if predicted_label == 1 else "not spam" # 返回分类结果 让我们在一个示例文本上尝试这个 `classify_review` 函数: text_1 = ( "You are a winner you have been specially" " selected to receive $1000 cash or a $2000 award." ) print(classify_review( text_1, model, tokenizer, device, max_length=train_dataset.max_length )) 模型正确地预测为“垃圾邮件”。我们再试一个示例: text_2 = ( "Hey, just wanted to check if we're still on" " for dinner tonight? Let me know!" ) print(classify_review( text_2, model, tokenizer, device, max_length=train_dataset.max_length )) 模型再次做出正确的预测,并返回“非垃圾邮件”标签。 最后,为了以后能够重用模型而无需重新训练,我们可以保存模型。使用 `torch.save` 方法: torch.save(model.state_dict(), "review_classifier.pth") 保存后,可以加载模型: model_state_dict = torch.load("review_classifier.pth", map_location=device) model.load_state_dict(model_state_dict)
点赞
热门评论
最新评论
匿名用户
+1
-1
·
回复TA
暂无热门评论
相关推荐
阅读更多资讯
热门评论 最新评论
暂无热门评论