星语课程网
「MySQL高级篇」explain分析SQL,索引失效&&常见优化场景
来源:本站编辑
2024-12-08 20:30
92
[TOC] #【一、explain】分析SQL ==================  explain中,包含了如下几个字段(不同版本可能会有所差异): |字段 | 含义 | | ------------ | ------------ | | id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 | | select\_type |表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等 | | table | 输出结果集的表 | |partitions | 查询时匹配到的分区信息,对于非分区表值为NULL,当查询的是分区表时,partitions显示分区表命中的分区情况。 | | type | 表示表的连接类型,性能由好到差的连接类型为( system ---> const -----> eq\_ref ------> ref -------> ref\_or\_null----> index\_merge ---> index\_subquery -----> range -----> index ------> all ) | |possible\_keys | 表示查询时,**可能使用**的索引 | | key | 表示查询时,**实际使用**的索引 | | key\_len |索引字段的长度,可用来区分长短索引 | |rows | 扫描行的数量| |filtered|表里符合条件的记录数所占的百分比| |extra|执行情况的说明和描述| > 看完是不是很懵,感觉好多要记忆的,别着急,下边我们通过实际案例,来加深记忆 id -- id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 id 情况有三种 : 1. 此处只是单表查询,id只有一个  2. id一样,则从上到下 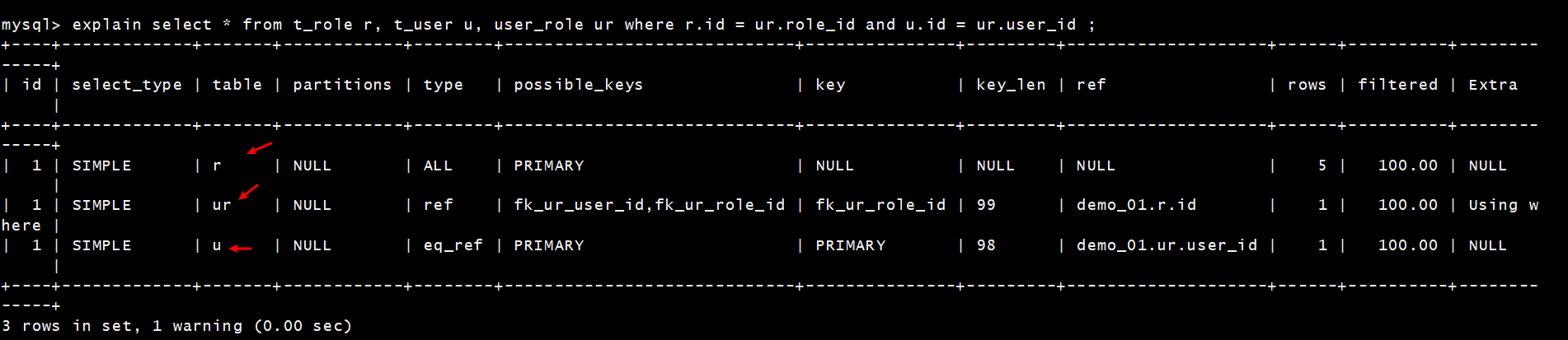 3. id不同,则id值越大,优先级越高 > 此处是嵌套子查询,最内部的子查询,自然是最先执行的  ### 简而言之: * id值越大,优先级越高; * id值一样,则从上到下; select\_type -- | select\_type | 含义 | | ------------ | ------------ | | SIMPLE | 简单的select查询,查询中不包含子查询或者UNION | | PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 | | SUBQUERY|在SELECT 或 WHERE 列表中包含了子查询 | |DERIVED|在**FROM 列表中包含的子查询**,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中| |UNION|若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED| |UNION RESULT|从UNION表获取结果的SELECT| ------------ ### PRIMARY,SUBQUERY  ### DERIVED(需要临时表,自然比上述效率低)  | type | 含义 | | ------------ | ------------ | | NULL | MySQL不访问任何表,索引,直接返回结果 | | system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 | |const|表示通过**索引**一次就找到了,const 常用于**primary key 或者 unique 索引(本质上都是唯一索引)**。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常量。const于将 "主键" 或 "唯一" 索引的所有部分与常量值进行比较| |eq\_ref|类似ref,区别在于使用的是**唯一索引**,使用主键的**关联查询**,关联查询出的记录只有一条。常见于主键或唯一索引扫描| |ref|**非唯一性索引**扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个)| |range|只检索给定返回的行,使用一个**索引**来选择行。 where 之后出现 between , < , > , in 等操作。| |index|index 与 ALL的区别为 index 类型只是**遍历了索引树**, 通常比ALL 快, ALL 是遍历数据文件。| |all|将遍历全表以找到匹配的行| ---- 结果值从最好到最坏以此是: NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL system > const > eq_ref > ref > range > index > ALL 一般至少要达到range级别,最好达到ref 。 ### const **唯一**索引,非关联查询 ### eq\_ref,ref eq\_ref 跟 const 的区别是:两者都利用唯一索引,但前者是关联查询,后者只是普通查询? eq\_ref 跟 ref 的区别:后者是**非唯一索引** ### index,all 都是读全表,区别在于index是遍历索引树读取,而ALL是从硬盘中读取。 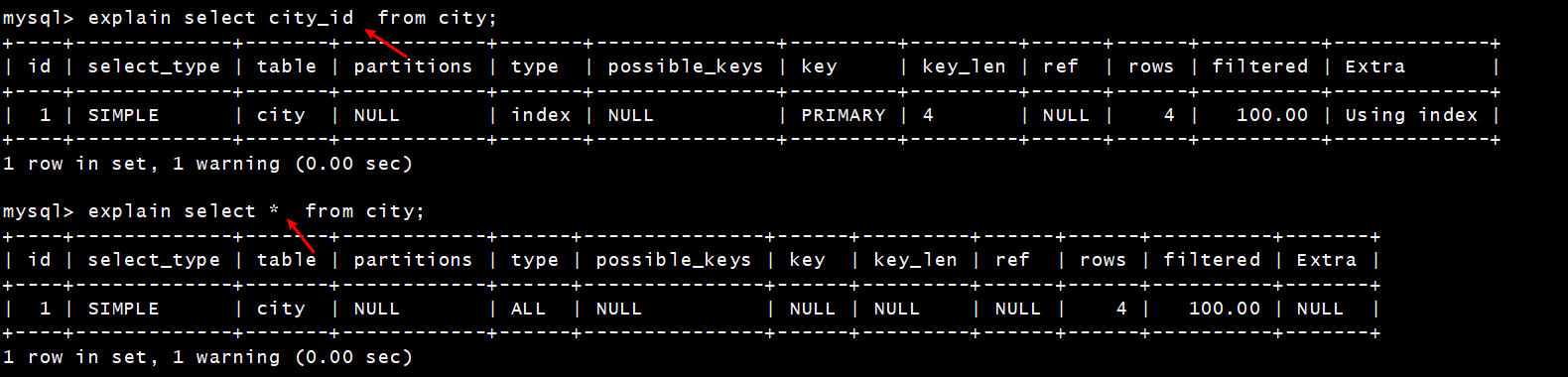 不走索引就会遍历全表  possible\_keys,key ------------------ possible\_keys : 显示可能应用在这张表的索引, 一个或多个。 key :**实际使用**的索引, 如果为NULL, 则没有使用索引。(可能是没有走索引,需要分析) key\_len : 表示索引中使用的字节数, 在不损失精确性的前提下, **长度越短越好 。** * 单列索引,那么需要将整个索引长度算进去; * 多列索引,不是所有列都能用到,需要计算查询中实际用到的列。  ref --- 显示**索引的哪一列**被使用了,如果可能的话,是一个常数。 * 当使用常量等值查询,显示const * 当关联查询时,会显示相应关联表的关联字段 * 如果查询条件使用了表达式、函数,或者条件列发生内部隐式转换,可能显示为func * 其他情况为null 1. id是索引,而且是id=1,一个常数,故ref = const 2. user\_id不是索引,ref直接为null 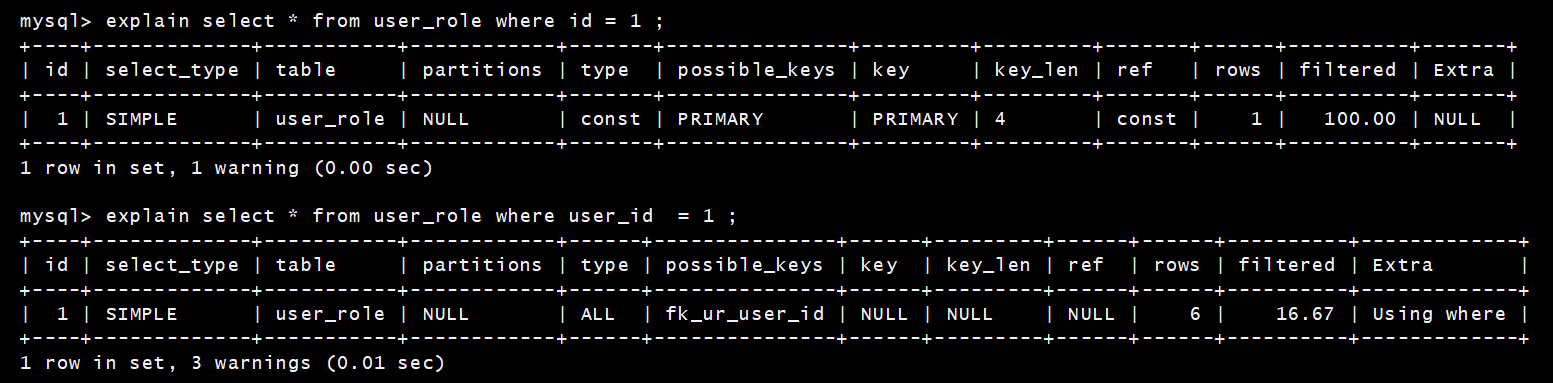 t1.id是索引,且=号后边不是常量,故显示t1.id,即显示相应关联表的关联字段  rows ---- > 扫描行的数量,一般越小越好 * 用索引 rows 就为1,**无论是唯一索引还是非唯一索引** * 其他情况一般是全表扫描,rows等于表的行数。 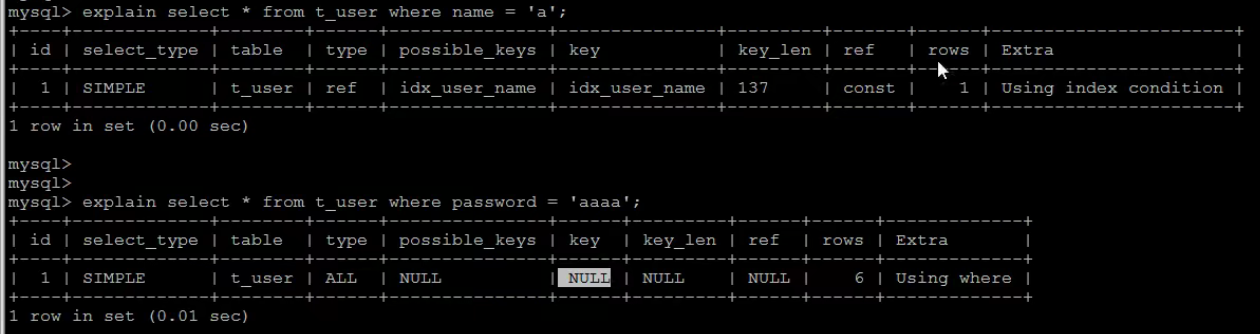 filtered -------- 表里**符合条件**的记录数的所占的百分比。 extra ----- 其他的额外的执行计划信息,在该列展示 ,需要把前两个优化为using index。 | EXTRA | 含义 | | ------------ | ------------ | | using filesort | 说明mysql会对数据使用一个**外部**的索引排序,而不是按照表内的索引顺序进行读取,表示**无法利用索引**完成的排序操作, 称为 “文件排序”, 效率低。 | | using temporary | 使用了**临时表**保存中间结果,MySQL在**对查询结果排序**时使用临时表。常见于 order by 和 group by; 效率低 | |using index|表示相应的select操作使用了**覆盖索引**, 直接从索引中过滤掉不需要的结果,无需回表, 效率不错。| |using index condition|**索引下推!!**查找使用了索引,但是需要**回表查询**数据,此时就是因为索引列没有完全包含查询列| > 具体using index condition中的索引下推是什么意思,可以参考这篇 [索引的原理&&设计原则](https://juejin.cn/post/7060427613742825502) ### using where > 不同版本好像不一样 5.7:表示 MySQL 首先从数据表(存储引擎)中读取记录,返回给 MySQL 的 server 层,然后在 server 层过滤掉不满足条件的记录,即无法直接在存储引擎过滤掉。 简单来说,就是查询时**where中用的不是索引。** 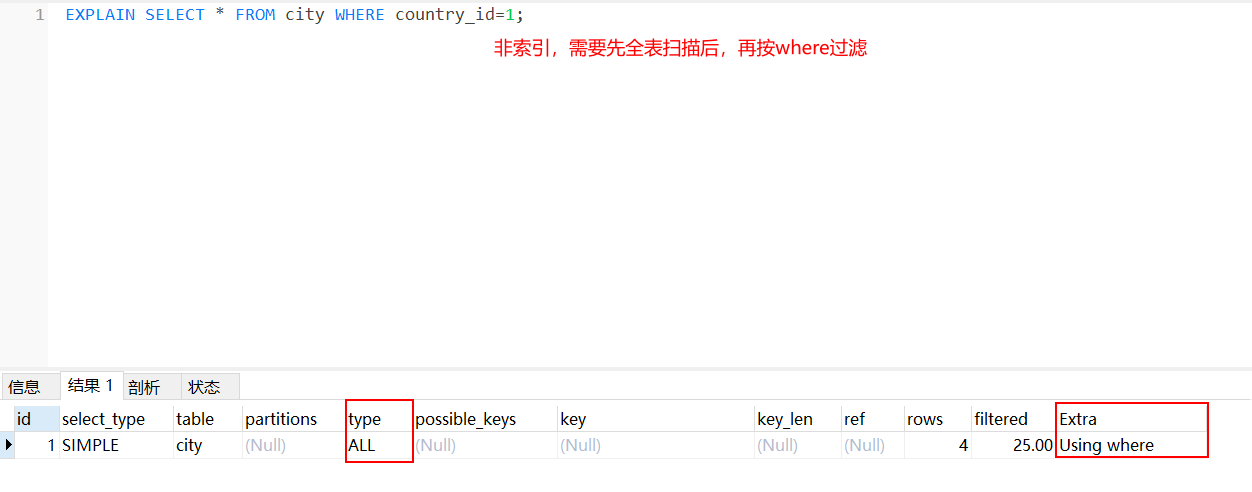 > 现在,我们知道怎么用explain来分析SQL语句了,自然可以来剖析我们的SQL语句的性能,不过早有先人给我们总结了几个需要优化的场景-->**索引失效** # 【二、索引失效】的几个场景 =============== ## 0\. SQL准备 --------- create table `tb_seller` ( `sellerid` varchar (100), `name` varchar (100), `nickname` varchar (50), `password` varchar (60), `status` varchar (1), `address` varchar (100), `createtime` datetime, primary key(`sellerid`) )engine=innodb default charset=utf8mb4; insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('alibaba','阿里巴巴','阿里小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('baidu','百度科技有限公司','百度小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('huawei','华为科技有限公司','华为小店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itcast','传智播客教育科技有限公司','传智播客','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itheima','黑马程序员','黑马程序员','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('luoji','罗技科技有限公司','罗技小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('oppo','OPPO科技有限公司','OPPO官方旗舰店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('ourpalm','掌趣科技股份有限公司','掌趣小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('qiandu','千度科技','千度小店','e10adc3949ba59abbe56e057f20f883e','2','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('sina','新浪科技有限公司','新浪官方旗舰店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('xiaomi','小米科技','小米官方旗舰店','e10adc3949ba59abbe56e057f20f883e','1','西安市','2088-01-01 12:00:00'); insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('yijia','宜家家居','宜家家居旗舰店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00'); -- 创建联合索引 create index idx_seller_name_sta_addr on tb_seller(name,status,address); ## 1\. 不满足最左前缀 ----------- 所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个**复合索引**:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效: 1. 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效  2. 出现跳跃的情况 * 直接第一层name都不走,当然都**失效** 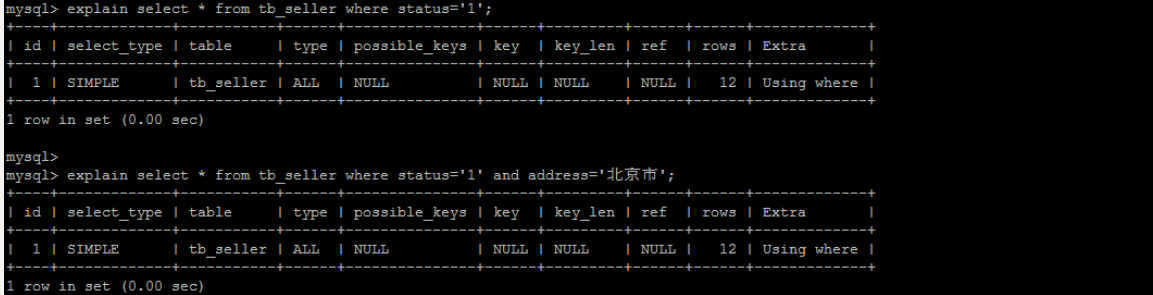 * 走了第一层,但是后续直接第三层,只有**出现跳跃情况前的不会失效(此处就只有name成功)**  * 同时,这个顺序并不是由我们where中的排列顺序决定,比如: * where name='小米科技' and status='1' and address='北京市' * where status='1' and name='小米科技' and address='北京市' 这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的 > 其实是因为我们MySQL有一个**Optimizer**(查询优化器),查询优化器会将SQL进行优化,选择最优的查询计划来执行。 ## 2\. 范围查询之后 ---------- 范围查询**之后**的索引字段,会失效!!!但本身用来范围查询的那个索引字段依然有效,如图中的status。 * 而图中address失效了,对比一下长度便可看出来。  ## 3\. 索引字段做运算 ----------- 对索引字段做运算,使用函数等都会导致索引失效。  ## 4\. 字符串不加' ' ------------ 索引字段为字符串类型,由于在查询时,没有对字符串加**单引号**,MySQL的查询优化器,会自动的进行类型转换,造成索引失效。 ## 5\. 避免select \* --------------- ### 危害 * 消耗更多的 CPU 和 IO 以网络带宽资源 * 可减少表结构变更带来的影响 * 无法使用**覆盖索引** ### 🎈覆盖索引 尽量使用**覆盖索引**(索引列完全包含查询列),减少select \* 当查询列中包含了非索引项,虽然我们还是能够利用到索引,但是为了获取非索引项字段,我们需要**回表**去查询数据,效率会比较低。 ## 6\. or分割开的条件 ------------ 用or分割开的条件, 如果**or前的条件中的列有索引**,而**后面的列中没有索引**,那么涉及的索引**都不会被用到**。 示例,name字段是索引列 , 而createtime不是索引列,中间是or进行连接是不走索引的 : * 因为有一个不走索引,又是or条件,两个都要判断一下,相当于不管如何,**都还是得去走全表查询,没有利用到索引。** explain select * from tb_seller where name='黑马程序员' or createtime = '2088-01-01 12:00:00'\G;  ## 7\. 以%开头的Like模糊查询 ----------------- 可以联系**字典树Trie的匹配**吧。 * 比如要找‘abc’,如果是%bc,一开始的根都找不到了,自然没办法利用到索引树 * 而如果是ab%,还能利用到前两个。 * %开头的失效,%结尾的还能利用索引(实际上这里就相当于字符串的最左前缀原则,可以这么理解) 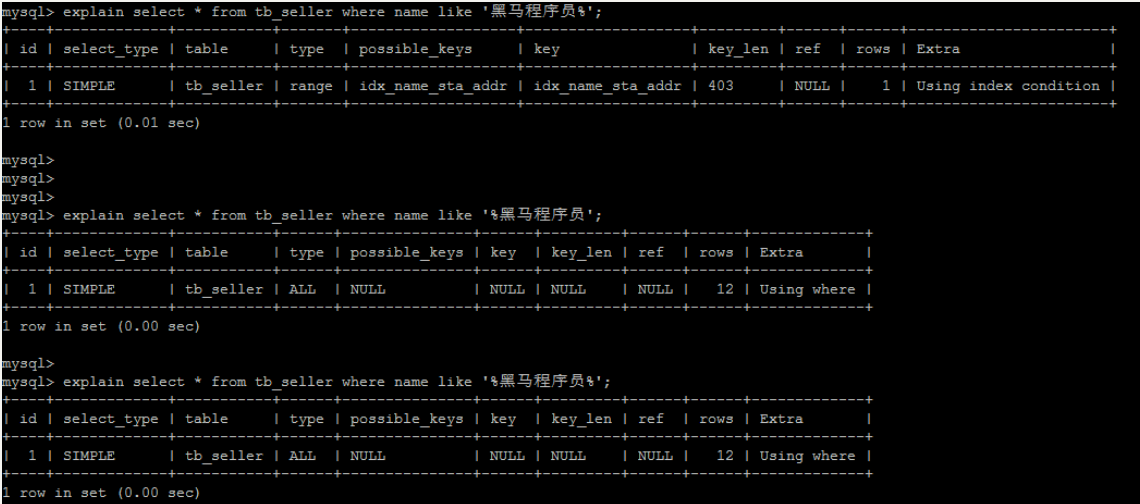 ### 解决方法:使用覆盖索引 当真的需要两边都使用%来模糊查询时,只有当 **作为模糊查询的条件字段**(例子中的name)以及 **想要查询出来的数据字段**(例子中的 name & status & address)**都在索引列上**时,才能真正使用索引。 > 关于覆盖索引,可以参考这篇 -> [索引原理,设计原则](https://juejin.cn/post/7060427613742825502) 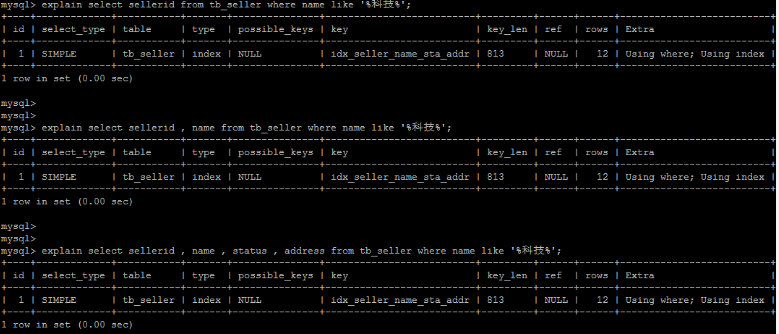 8\. MySQL认为全表更快 ---------------  此处是由于数据的特殊性,‘北京市’所占的比例很高,还不如全表扫描  ### 8.1 is null 和 is not null > 本质上**跟上边是一样的** _MySQL底层会自动判断,如果全表扫描快,则直接使用全表扫描,不走索引。如果表中该索引列数据绝大多数是非空值,则使用 is not null的时候走索引,使用 is null的时候不走索引(还不如全表扫描快),全表扫描;反之亦然。_ __ 如果表中is null的比较多,那自然就直接全表扫描,如果is null的很少,会走索引。 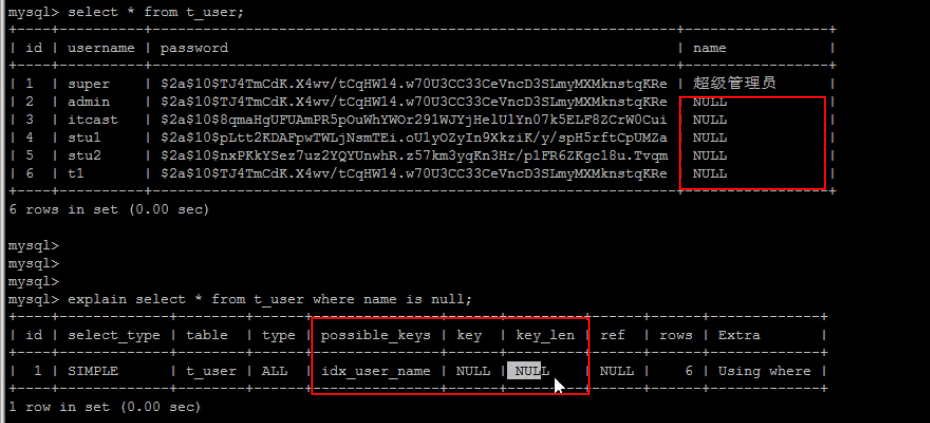 ## 8.2 in 和 not in 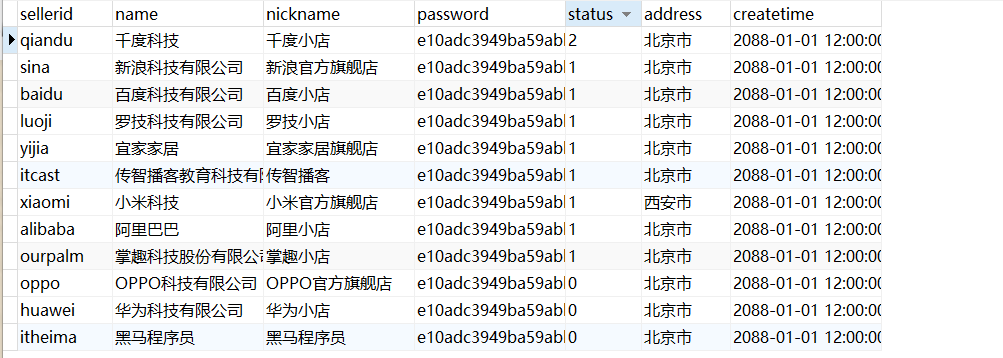 为了方便测试,我们单独建了一个status索引,观察该表数据,status中2很少,而1很多。 所以in('1')的话,不如走全表,没有用到索引 in('2')就会走索引 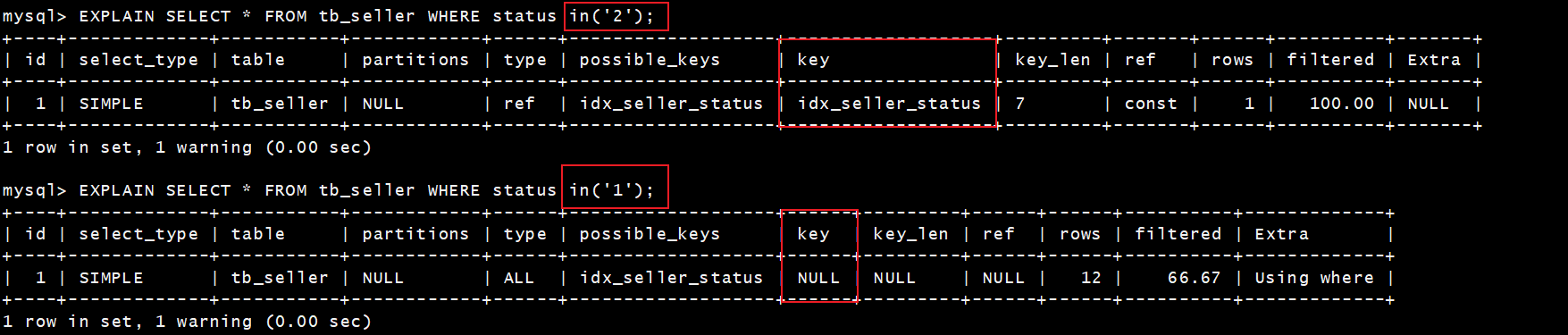 ### 总结 我们建立索引的时候,对于**数据分布均匀且重复的字段**,我们一般不考虑对其添加索引,因为此时MySQL会认为全表更快,会走全表扫描而非索引,导致我们的索引失效。 ## 9\. !=或者<> ---------- 使用不等式也会导致索引失效 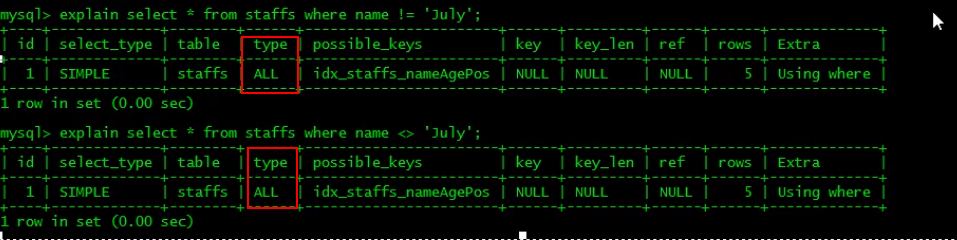 相关习题 ----  > 说完几个**索引失效的场景**,下边呢,是我们**具体的应用场景**,在如下几种特定情况下,我们需要采取不同的SQL优化方式,或采用索引,或利用外部条件 #【三、优化场景】1. 大批量插入数据 ==================== 环境准备 ---- CREATE TABLE `tb_user_2` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(45) NOT NULL, `password` varchar(96) NOT NULL, `name` varchar(45) NOT NULL, `birthday` datetime DEFAULT NULL, `sex` char(1) DEFAULT NULL, `email` varchar(45) DEFAULT NULL, `phone` varchar(45) DEFAULT NULL, `qq` varchar(32) DEFAULT NULL, `status` varchar(32) NOT NULL COMMENT '用户状态', `create_time` datetime NOT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`) -- 唯一性约束 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ; load命令 ------ 适当的设置可以提高导入的效率。  对于 InnoDB 类型的表,有以下几种方式可以提高导入的效率: ### 1) 主键顺序插入 因为InnoDB类型的表是**按照主键的顺序**保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。如果InnoDB表没有主键,那么系统会自动默认创建一个内部列作为主键,所以如果可以给表创建一个主键,将可以利用这点,来提高导入数据的效率。 脚本文件介绍 : sql1.log ----> 主键有序 sql2.log ----> 主键无序 插入主键顺序排列数据:  主键无序:  #### 出现了权限问题  执行:set global local\_infile=on; #### 但又出现了另一个问题:  其实我们开启之后, 需要**退出重新连接**,再次连接时便可以正常操作了 * 如果还是不行的话,连接的时候可以这样连接: mysql --local_infile=1 -u root -ppassword ### 2)关闭唯一性校验 _在**导入数据前**执行 SET UNIQUE\_CHECKS=0,关闭唯一性校验,在**导入结束后**执行 SET UNIQUE\_CHECKS=1,恢复唯一性校验,可以提高导入的效率。_ 🎪2. order by 排序 ================ 环境准备 ---- CREATE TABLE `emp` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(100) NOT NULL, `age` int(3) NOT NULL, `salary` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300'); insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500'); insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800'); insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500'); insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200'); insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300'); insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700'); insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500'); insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400'); insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100'); insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900'); insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500'); create index idx_emp_age_salary on emp(age,salary); 两种排序方式 ------ ### using index 直接能在索引列完成查询,无需回表,关于回表查询,可以参考 [这篇文章](https://juejin.cn/post/7060427613742825502) ,此时需要保证**所查询的字段**都是**索引字段**,才会是using index  > 但这个不太现实,不可能说我们要查的,都是索引的字段,所以很多情况下,我们并没有办法把using filesort优化为using index,只能退而求其次,尽量从filesort的角度去优化,通过外部条件。 ### 🎑using filesort  #### 何时会出现: 1. order by的字段不是索引 2. order by 字段是索引字段,但是 select 中没有使用**覆盖索引** 3. order by 中同时存在 ASC 升序排序和 DESC 降序排序 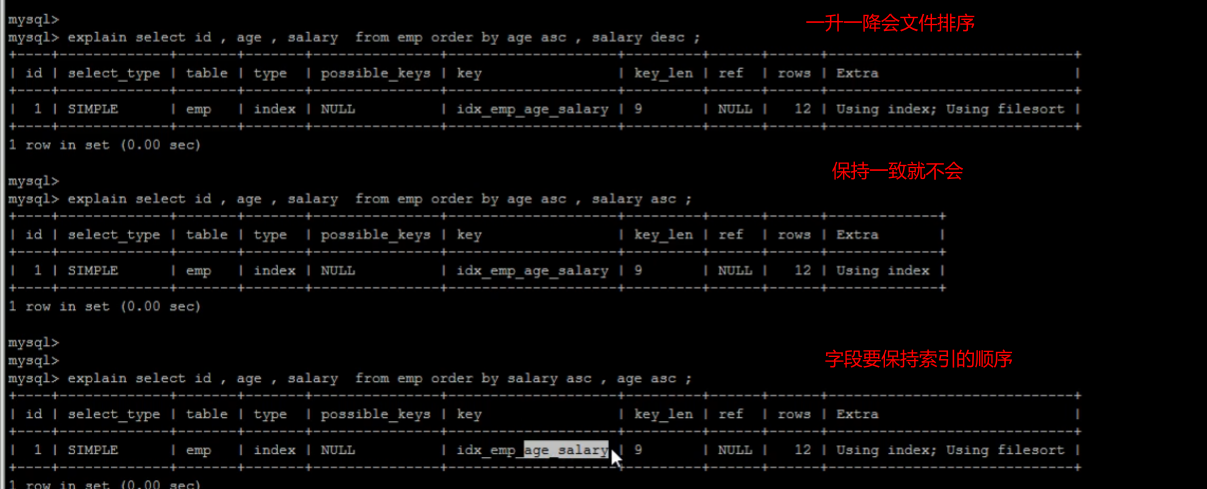 4. order by中用到的是复合索引,但没有保持复合索引中字段的**先后顺序(即违背了最左前缀原则)** > 比如图中的 select id,age,salary from emp order by salary,age; 为什么呢?这里我们得回顾一下复合索引是如何存储的,比如:我们建立一个复合索引(name,status,address),索引中也是按这个字段来存储的,类似图中表格这样: 复合索引树(只存储索引列和主键用于回表),而且是**先按name排序**,name相同了**再按status排序**,以此类推 name status address id(主键) 小米1 0 1 1 小米2 1 1 2 所以如果我们不按照**索引的先后顺序**来order by的话,就跟索引树中的排序规则不一样了,索引此时排好的序,我们都没办法合理利用到,自然MySQL不会去走索引了。 🎏Filesort的优化 ------------- ### 两种扫描算法 对于Filesort , MySQL 有两种排序算法: 以这条SQL语句为例,我们来看看他是怎么执行的: select * from emp where age=1 order by salary; 1) **两次扫描算法** :MySQL4.1 之前,使用该方式排序。 ①首先根据where条件,过滤得到相应的满足age=1的salary,取出**排序字段salary**和对应的**行指针信息**(用于回表),然后在排序区 **sort buffer** 中排序,如果sort buffer不够,则在临时表 temporary table 中存储排序结果。 ②完成排序之后,再根据**行指针回表读取所有字段**,而次该操作可能会导致大量随机I/O操作,是我们需要改进的地方。 这就是所谓的两次扫描,第一次扫描,我们拿到的只是排序字段,然后在**sort buffer**排好序;第二次扫描,才去**回表**读取所有字段,最终返回。 > 该如何优化呢?为什么要分成两次,有没有一种可能是空间不够呢?那我们如果有足够的空间,以空间换时间,是不是就可以开辟出一种新的方法,只需要一次扫描即可 2)**一次扫描算法**:一次性取出满足条件的**所有字段**,然后在排序区 sort buffer 中排序后直接输出结果集。排序时内存开销较大,但是排序效率比两次扫描算法要高,典型的以空间换时间的思想。 具体使用哪种算法呢? MySQL 通过比较系统变量 **max\_length\_for\_sort\_data** 的大小和 **Query语句取出的字段总大小**, 来判定使用那种排序算法,如果**max\_length\_for\_sort\_data** 更大,那么使用**一次扫描算法**;否则使用两次扫描算法。 ### 优化方案 ① 增大前者 **max\_length\_for\_sort\_data** 可以适当 **max\_length\_for\_sort\_data** 系统变量,来增大排序区的大小,提高排序的效率,这是典型的**空间换时间**的思想。 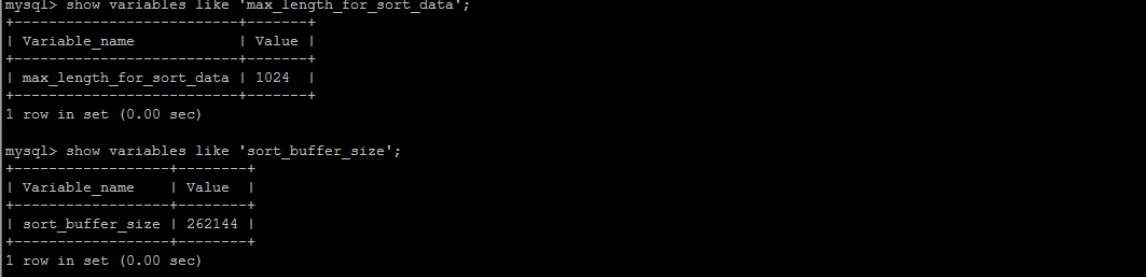 ② 减小后者 **Query语句取出的字段总大小** 如果内存实在不够富裕的话,我们可以减少查询的字段,避免select \* ③ 提高 **sort\_buffer\_size** : 由上文可知,通过增大该参数,可以让 MySQL 尽量减少在排序过程中对须要排序的数据**进行分段**,避免需要使用到临时表 temporary table 来存储排序结果,再把多次的排序结果串联起来。 可惜,MySQL**无法查看**它用了哪个算法。如果增加了max\_Length\_for\_sort\_data变量的值,磁盘使用率上升了,CPU使用率下降了,并且Sort\_merge\_passes状态变量相对于修改之前开始很快地上升,也许是MySQL强制让很多的排序使用了**一次扫描算法**。 > 具体的实战修改过程,需要结合MySQL中另一个工具--**trace分析优化器**,来分析执行计划,后续有机会,我们再来详细聊一聊! 3\. group by 分组 =============== 由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作。当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算。所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引。 1\. 使用索引 -------- 先来看看无索引的情况:using temporary;using filesort  ### 创建索引 create index idx_emp_age_salary on emp(age,salary);  2\. 加上order by null 禁止排序 ------------------------ 如果查询包含 **group by** 但是用户想要避免排序结果的消耗, 则可以执行order by null 禁止排序。如下 : 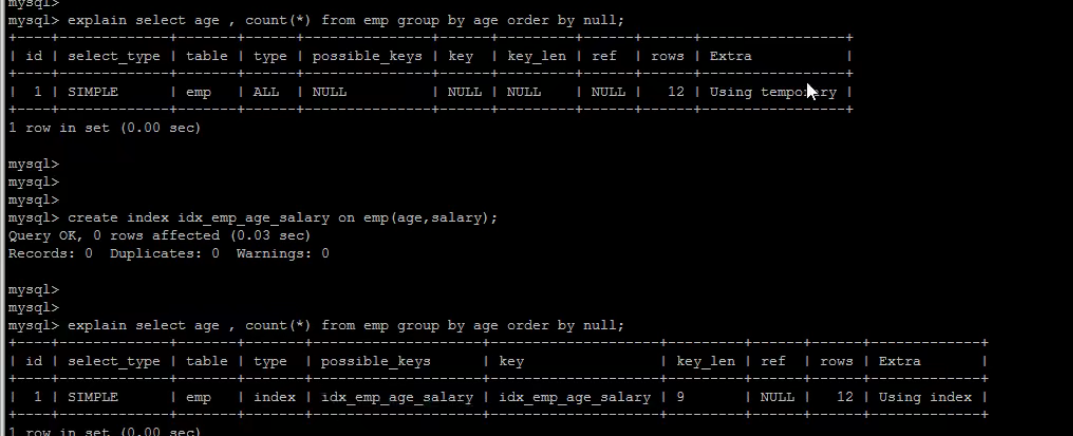 3\. 需要排序 (则跟order by的优化大体相同) ---------------------------- 4\. 优化子查询 ========= Mysql4.1版本之后,开始支持SQL的子查询。这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中。使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,同时也可以避免事务或者表锁死,并且写起来也很容易。 但是,有些情况下,子查询是可以被更高效的**连接(JOIN)替代的**!! __ 示例 ,查找有角色的所有的用户信息 : explain select * from t_user where id in (select user_id from user_role ); 执行计划为 :  优化后 : explain select * from t_user u , user_role ur where u.id = ur.user_id;  > 连接(Join)查询之所以更有效率一些 ,是因为MySQL不需要在内存中**创建临时表**来完成这个逻辑上需要两个步骤的查询工作。 5\. 优化OR条件 ========== 对于包含OR的查询子句,如果要利用索引,则OR之间的**每个条件列都必须用到索引** , 而且**不能使用到复合索引**; 如果没有索引,则应该考虑增加索引。 我们此处有一个id主键索引,和一个age,salary复合索引:  单列+复合中的某一个 ---------- explain select * from emp where id = 1 or age = 30;  单列+单列(两个一样) ----------- > 实际上等效于range,此处只是提供一个示例  解决:使用union优化!!! --------------- ### 优化前 * type:index\_merge  ### 优化后 * type:一个是const,一个是ref,都比index快  6\. 使用SQL提示 =========== SQL提示,是优化数据库的一个重要手段,简单 来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。 use index --------- 在查询语句中表名的后面,添加 use index 来提供希望MySQL去**参考**的索引列表,就可以让MySQL不再考虑其他可用的索引。  ingore index ------------ 如果用户只是单纯的想让MySQL忽略一个或者多个索引,则可以使用 ignore index 作为 hint 。 force index ----------- 强制走索引,即使MySQL认为全表更快,我们用force也可以强制走索引。 ### 跟use的区别 * use只是提供一个参考,具体用不用还得看MySQL的优化器怎么想的 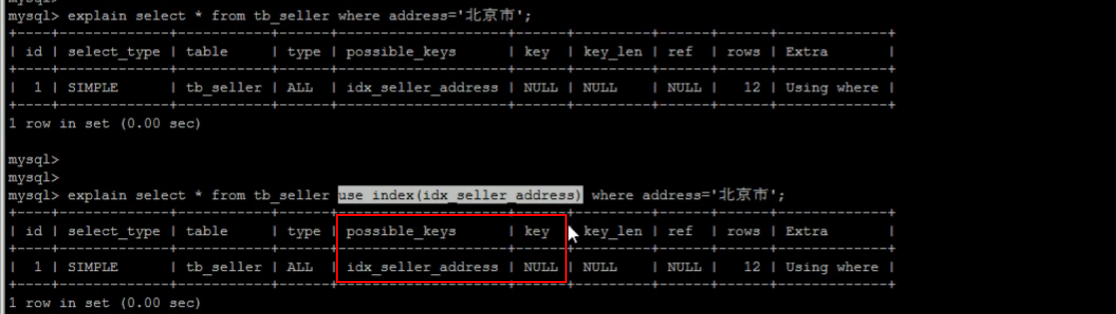 ✨7. 优化limit分页 ============= 一个常见又非常头疼的问题就是 limit 2000000,10 ,此时需要MySQL_**排序**_ 前2000010 记录,仅仅返回2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大 。 比如我们有这样一条语句,select \* from tb\_item limit 2000000,10 ; 此时默认是根据 **id** 排序的。 #### 优化思路一 在**索引上**完成排序分页操作,最后根据**主键关联**回原表查询所需要的其他列内容。  #### 优化思路二 该方案适用于**主键自增**的表,可以把Limit 查询转换成某个位置的查询 。(局限性:主键不能断层) * 如果要根据其他字段来排序的话,此方法就无法做到了。  8\. 优化insert操作 ============== 一次连接,多次插入 --------- 比如我们需要插入三条数据: insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); 此时需要建立三次连接,每次连接都要消耗资源,为了提高单次连接的执行效率,我们会采取: insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry'); 同时,insert的时候最好是保持数据的**有序插入** 🎊总结 ==== 1. explain分析SQL中,其中比较重要的主要是type,key,ref以及extra,我们不需要死记硬背,多拿几条语句去explain比对比对,更有利于我们辅助记忆。 2. 索引失效的几个场景,借用b站热评: 全值匹配我最爱,最左前缀要遵守; 带头大哥不能死,中间兄弟不能断; 索引列上少计算,范围之后全失效; Like百分写最右,覆盖索引不写星; 不等空值还有or,索引失效要少用; VAR引号不可丢,SQL高级也不难! 3. 优化基本原则:巧用索引,减少连接次数。
点赞
热门评论
最新评论
匿名用户
+1
-1
·
回复TA
暂无热门评论
相关推荐
阅读更多资讯
热门评论 最新评论
暂无热门评论